Affiliation:The University of Tokyo
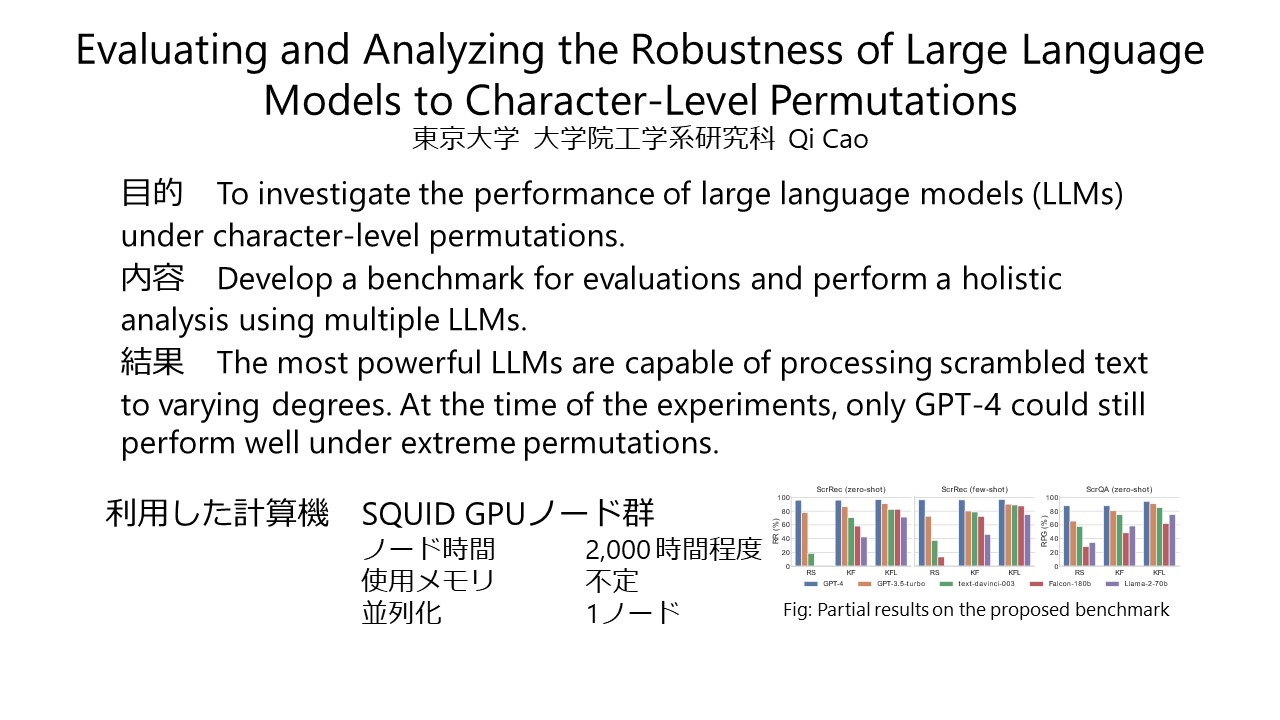
Abstract:While Large Language Models (LLMs) have achieved remarkable performance in many tasks, much about their inner workings remains unclear. In this study, we present novel experimental insights into the resilience of LLMs, when subjected to extensive character-level permutations. To investigate this, we first propose the Scrambled Bench, a suite designed to measure the capacity of LLMs to handle scrambled input, in terms of both recovering scrambled sentences and answering questions given scrambled context. The experimental results indicate that most powerful LLMs demonstrate the capability akin to typoglycemia, a phenomenon where humans can understand the meaning of words even when the letters within those words are scrambled, as long as the first and last letters remain in place. More surprisingly, we found that only GPT-4 nearly flawlessly processes inputs with unnatural errors, even under the extreme condition, a task that poses significant challenges for other LLMs and often even for humans. Specifically, GPT-4 can almost perfectly reconstruct the original sentences from scrambled ones, decreasing the edit distance by 95%, even when all letters within each word are entirely scrambled. It is counter-intuitive that LLMs can exhibit such resilience despite severe disruption to input tokenization caused by scrambled text.
Publication related to your research:
(International conference paper)
- Qi Cao, Takeshi Kojima, Yutaka Matsuo, Yusuke Iwasawa. "Unnatural error correction: GPT-4 can almost perfectly handle unnatural scrambled text", Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.8898-8913, Dec. 2023.
Posted : March 31,2024
