更新日時:2024年04月04日 / OCTOPUS
OCTOPUS retired on March 29, 2024.
OCTOPUS (Osaka university Cybermedia cenTer Over-Petascale Universal Supercomputer) is a cluster system starts its operation in December 2017. This system is composed of different types of 4 clusters, General purpose CPU nodes, GPU nodes, Xeon Phi nodes and Large-scale shared-memory nodes, total 319 nodes.
System Configuration
| Theoretical Computing Speed | 1.463 PFLOPS | |
|---|---|---|
| Compute Node | General purpose CPU nodes 236 nodes (471.24 TFLOPS) |
CPU : Intel Xeon Gold 6126 (Skylake / 2.6 GHz 12 cores) 2 CPUs Memory : 192GB |
| GPU nodes 37 nodes (858.28 TFLOPS) |
CPU : Intel Xeon Gold 6126 (Skylake / 2.6 GHz 12 cores) 2 CPUs GPU : NVIDIA Tesla P100 (NV-Link) 4 units Memory : 192GB |
|
| Xeon Phi nodes 44 nodes (117.14 TFLOPS) |
CPU : Intel Xeon Phi 7210 (Knights Landing / 1.3 GHz 64 cores) 1 CPU Memory : 192GB |
|
| Large-scale shared-memory nodes 2 nodes (16.38 TFLOPS) |
CPU : Intel Xeon Platinum 8153 (Skylake / 2.0 GHz 16 cores) 8 CPUs Memory : 6TB |
|
| Interconnect | InfiniBand EDR (100 Gbps) | |
| Stroage | DDN EXAScaler (Lustre / 3.1 PB) | |
* This is an information on July 21, 2017. Therefore, there may a bit of a discrepancy about performance values. Thank you for your understanding.
Gallery



![]()
![]()
![]()
Technical material
Please see following page:
ペタフロップス級ハイブリッド型スーパーコンピュータ OCTOPUS : Osaka university Cybermedia cenTer Over-Petascale Universal Supercomputer ~サイバーメディアセンターのスーパーコンピューティング事業の再生と躍進にむけて~ [DOI: 10.18910/70826]
更新日時:2021年02月28日 / SX-ACE
SX-ACE is terminated on Feb 28, 2021.
| to 31 March, 2020 | from 1 April, 2020 to 28 February, 2021 | |
|---|---|---|
| Number of cluster | 3 | 2 |
| Number of nodes(total) | 1536 | 1024 |
| Number of cores(total) | 6144 | 4096 |
| Peak performance(total) | 423TFLOPS | 282TFLOPS |
| Vector performance(total) | 393TFLOPS | 262TFLOPS |
| Number of memory(total) | 96TB | 64TB |
| Storage | 2PB(No change) | |
Please keep in mind that SX-ACE service is partly changed as follows after Nov. 30, 2020, due to the replacement work and the contract of SX-ACE system.
- Technical support is NOT available.
- You can NOT "application resource request" and "first application for system use". In case that you use up node-hour of computing resources and storage resources from Dec. 1 to Feb. 28, you cannot add any computing/storage resource. So, we recommend you to add any resource in advance before Nov. 30, 2020.
- You can use shared-use node hour, dedicated-use node, disk(home, ext) which you are currently using, by Feb 28, 2021.
- The additional payment is not necessary for the use of dedicated-use node and disk from Dec.1 to Feb.28.
System overview
The Cybermedia Center has introduced the SX-ACE, which is a “clusterized” vector-typed supercomputer, composed of 3 clusters, each of which is composed of 512 nodes. Each node equips a 4-core multi-core CPU and a 64 GB main memory. These 512 nodes are interconnected on a dedicated and specialized network switch, called the IXS (Internode Crossbar Switch) and forms a cluster. Note that the IXS interconnects 512 nodes with a single lane of a 2-layer fat-tree structure and as a result exhibits 4 GB/s for each direction of input and output between nodes. In the Cybermedia Center, a 2 Peta-byte storage is managed on NEC Scalable Technology File System (ScateFS), a NEC-developed fast distributed and parallel file system, so that it can be accessed from large-scale computing systems including SX-ACE at the Cybermedia Center.
Node performance
Because a node has a multi-core vector-typed processor composed of 4 cores, each of which exhibits a 64 GFlops vector performance, and a 64GB main memory, the vector performance becomes 256 GFlops. On the other hand, the maximum transfer between the CPU and the main memory is 256 GB/s. This fact means that a SX-ACE node achieves a high memory-bandwidth performance of 1 Byte/Flops by taking a higher CPU performance into consideration. Moreover, the SX-ACE is suitable for the purpose of weather/climate and fluid simulation.
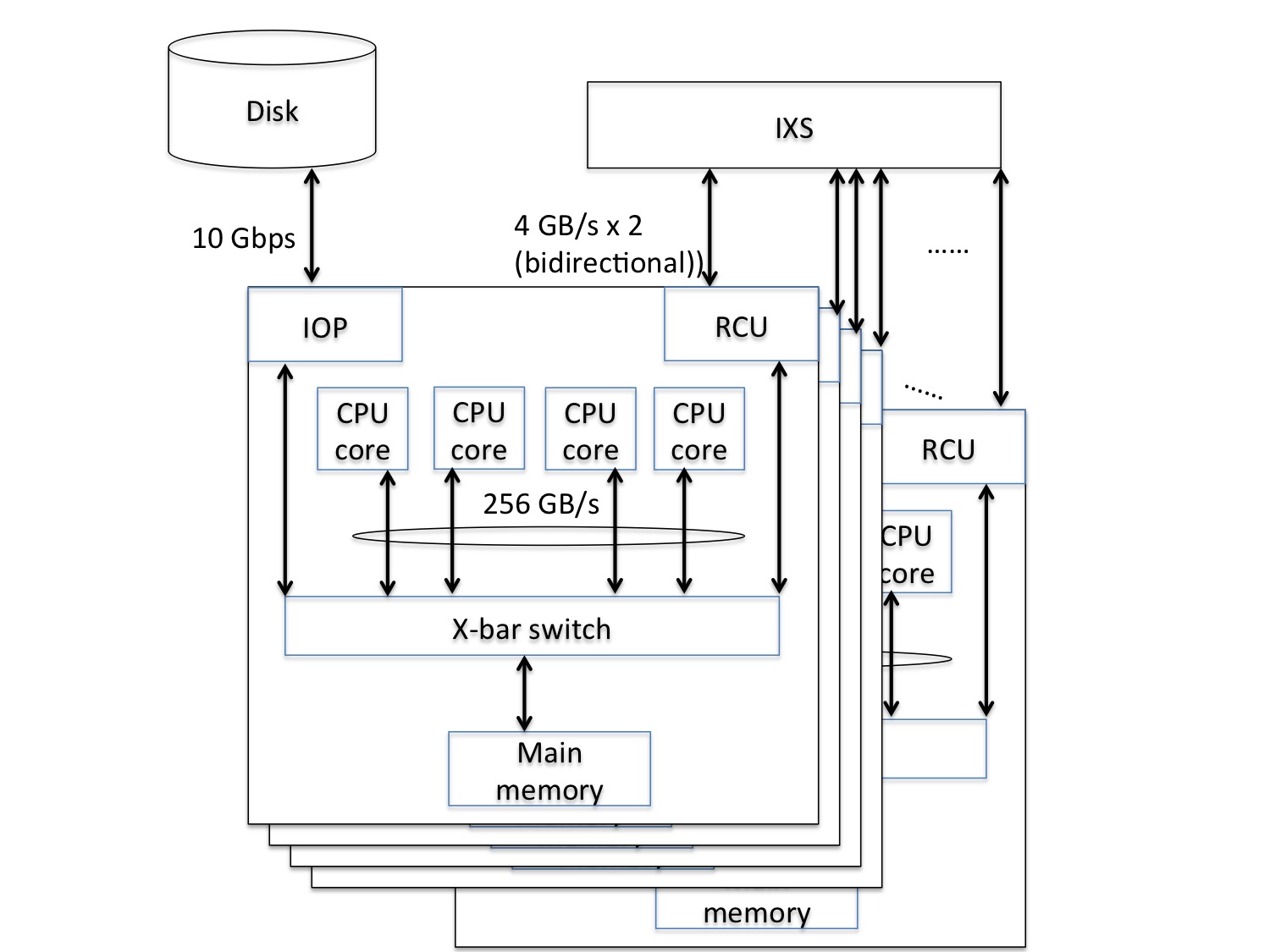
System performance
The Cybermedia Center has introduced the SX-ACE, which is composed of 3 clusters (1536 nodes in total). Therefore, the theoretical peak performance of 1 cluster and of 3 clusters is derived as follows:
|
SX-ACE
|
|||
| Per-node | 1cluster(512node) | Total(3cluster) | |
| # of CPU | 1 | 512 | 1536 |
| # of core | 4 | 2048 | 6144 |
| Performance | 276GFLOPS | 141TFLOPS | 423TFLOPS |
| Vector performance | 256GFLOPS | 131TFLOPS | 393TFLOPS |
| Main memory | 64GB | 32TB | 96TB |
| Storage | 2PB | ||
Importantly, note that performance is the sum of the vector-typed processor and the scalar processor deployed on SX-ACE. SX-ACE has a 4-core multi-core vector-typed processor and a single scalar processor.
Software
SX-ACE in our center has Super-UX R21.1 installed as the operating system. The Super-UX is based on System V UNIX and provides a high degree of user-experience. Furthermore, this operating system makes full use of the inherent hardware performance of SX-ACE. Because the Super-UX was introduced on SX-8R and SX-9, which the Cybermedia Center had provided as operating system, it is familiar and easy-to-use for experienced users of SX-8R and SX-9.
Also, on the SX-ACE at the CMC, the following software and library, in which performance tuning is applied, are available:
| SX-ACE | |
|---|---|
| Category | Function |
| Software for developer | Fortran 95/2003 compiler C/C++ compiler |
| MPI library | MPI/SX |
| HPF compiler | HPF/SX V2 |
| Debugger | dbx/pdbx |
| FTRACE | PROGINF/FILEINF FTRACE prof |
| Library for numerical calculation | ASL |
| Library for statistic calculation | ASLSTAT |
| Library for methematic | MathKeisan |
| Front-end node | |
|---|---|
| Category | Function |
| Software for developer | Fortran 95/2003 cross-compiler C/C++ cross-compiler Intel Cluster Studio XE |
| HPF compiler | HPF/SX V2 cross-compiler |
| Debugger | NEC Remote Debugger |
| Performance analysis tool | FTRACE NEC Ftrace Viewer |
| Visualization software | AVS/ExpressDeveloper |
| Software for computational chemistry | Gaussian09 |
An integrated scheduler composed of a JobManipulator and NQSII is used for job management on SX-ACE.
More details about the scheduler are provided here.
Performance tuning on SX-ACE
The SX-ACE is a distributed memory-typed supercomputer interconnecting the small-sized nodes described above, while the vector-typed supercomputers SX-8R and SX-9, provided by the Cybermedia Center, are a shared memory-typed supercomputer where multiple vector-typed CPUs calculate. Under this type of distributed memory-typed supercomputer, computation requires internode communication among nodes with different address spaces. Therefore, for performance tuning on SX-ACE, users are required to have basic knowledge about the internal architecture of nodes, internode structures, and communication characteristics.
Performance tuning techniques on SX-ACE are roughly categorized into two classes of intra-node parallelism (shared-memory parallel processing) and inter-node parallelism (distributed-memory parallel processing). The former parallelism distributes the computational workload to 4 cores on a multi-core vector-typed CPU in SX-ACE, while the latter parallelism distributes the computational workload onto multiple nodes.
Intra-node parallelism (shared-memory parallel processing)
The characteristic of this parallelism is that 4 cores of a multi-core vector-typed CPU shares a 64GB main memory. In general, shared-memory parallel processing is easier in terms of programming and performance tuning than distributed-memory parallel processing. This is true of the SX-ACE so that the intra-node parallelism is easier than the inter-node parallelism.
Representative techniques for Intra-node parallelism on SX-ACE are “Auto parallelism” and “OpenMP”.
This parallelism detects loop structures and instruction sets which the compiler can parallelize. Basically under this parallelism, developers do not need to add and modify their source codes. Developers only need to specify auto-parallelism as a compiler option. The compiler generates an execution module runnable in parallel. In the SX-ACE at the CMC, auto-parallelism is set by feeding a "-P auto" option to the compiler.
If your source code cannot take advantage of auto-parallelism or developers want to turn off the option, they can insert compiler directives to their source code to control auto-parallelism. Detailed information is available here.
OpenMP defines a suite of APIs(Application Programming Interfaces) for shared-memory parallel programming. As the name indicates, OpenMP targets a shared-memory architecture computer. As the following example shows, simply by inserting compiler directives, which are instructions to the compiler, to the source code and then compiling the source code, developers can generate a multi-threaded execution module. Therefore, OpenMP is an easy parallel programming method even the beginner can undertake with ease. The OpenMP can be used in Fortran, C and C++.
ex)1
#pragma omp parallel
{
#pragma omp for
for(i =1; i < 1000; i=i+1) x[i] = y[i] + z[i]; }
ex)2
!$omp parallel
!$omp do
do i=1, 1000
x(i) = y(i) + z(i)
enddo
!$omp enddo
!$omp end parallel
Useful information and TIPS on OpenMP can be available from books and the Internet.
Inter-node parallelism (distributed memory parallel processing)
The characteristic of this parallelism is that it leverages multiple independent memory spaces of distributed nodes, rather than share an identical memory space due to the fact that this parallelism uses multiple nodes. This fact makes this distributed memory parallel processing more difficult than shared-memory parallel processing.
The characteristic of this parallelism is that it leverages multiple independent memory spaces of distributed nodes, rather than share an identical memory space due to the fact that this parallelism uses multiple nodes. This fact makes this distributed memory parallel processing more difficult than shared-memory parallel processing.
A Message Passing Interface provides a set of libraries and APIs for distributed parallel programming based on a message-passing method. Based on considerations of communication patterns that will most likely happen on distributed-memory parallel processing environments, the MPI offers intuitive API sets for peer-to-peer communication and collective communications, in which multiple processes are involved, such as MPI_Bcast and MPI_Reduce. Under MPI parallelism, developers must write a source code by considering data movement and workload distribution among MPI processes. Therefore, MPI is a somewhat more difficult parallelism for beginners. However, developers will learn to write a source code that can run faster than the codes with HPF, once they become intermediate and advanced programmers that can write a source code by considering hardware architecture and other characteristics. Furthermore, MPI has become a de facto standard utilized by many computer simulations and analysis. Moreover, today's computer architecture has become increasingly "Clusterized" and thus, mastering MPI is preferred.
The HPF (High Performance Fortran) is a version of Fortran into which extensions targeting distributed-memory parallel computers is built, which has become an international standard.
Like OpenMP, HPF allows developers to automatically generate an execution module executed by multiple processes simply by inserting compiler directives pertaining to the parallelism of data and processing to source codes. Since the compiler generates instructions related to inter-process communication and synchronization necessary for parallel computation, this parallelism is a relatively easy method for the beginners to realize inter-node parallelism. As the name indicates, HPF is an extension of Fortan and thus, cannot be used in C.
例
!HPF$ PROCESSORS P(4)
!HPF$ DISTRIBUTE (BLOCK) ONTO P :: x,y,z
do i=1, 1000
x(i) = y(i) + z(i)
enddo
| SX-9 | SX-ACE | |
|---|---|---|
| # of CPU(# of core) | 16 CPU | 1 CPU (4core) |
| Peak vector performance | 1.6 TFLOPS | 256 TFLOPS (x1/6.4) |
| Main memory | 1 TB | 64 GB (x1/16) |
更新日時:2020年03月30日 / VCC
This service ended.
System overview
The PC cluster for a large-scale visualization (VCC) is a cluster system composed of 65 nodes. Each node has 2 Intel Xeon E5-2670v2 processors and a 64 GB main memory. These 62 nodes are interconnected on InfiniBand FDR and form a cluster.
Also, this system has introduced ExpEther, a system hardware virtualization technology. Each node can be connected with extension I/O nodes with GPU resource, and SSD on a 20Gbps ExpEther network. A major characteristic of this cluster system is that it is reconfigured based on a user’s usage and purpose by changing the combination of nodes and extension I/O nodes.
In our center, a 2 PB storage system is managed with a NEC-developed fast distributed parallel file system called ScaTeFS (Scalable Technology File System). The large-scale computing system including VCC can access this storage system.
Node performance
Each node has 2 Intel Xeon E5-2670v2 processors (200 GFlops) and a 64 GB main memory. An Intel Xeon E5-2670v2 processor runs at 2.5 GHz operating frequency with 10 cores. Performance of the processor is at 200 GFlops. Thus, a single node has 20 cores in total and exhibits 400 GFlops performance.
Internode communication takes place on an InfiniBand FDR network which provides 56 Gbps (bi-directional) as maximum transfer capability.
| 1node (vcc) | |
|---|---|
| # of processor (core) | 2(20) |
| main memory | 64GB |
| disk | 1TB |
| performance | 200GFlops |
System Performance
The PC cluster for the large-scale visualization (VCC) is composed of 65 nodes. From this, the theoretical peak performance is calculated as follows.
| PC cluster for large-scale visualization (VCC) | |
|---|---|
| # of processor (core) | 130(1300) |
| main memory | 4.160TB |
| disk | 62TB |
| performance | 26.0TFlops |
Also, the following reconfigurable resources can be attached to each node of VCC through the use of ExpEther, a system hardware virtualization technology, according to the users’ needs. At present, the reconfigurable resources are as below.
Not all reconfigurable resources can be attached to a node, and the maximum number of resources that can be attached to a node is limited. However, an arbitrary combination of resources such as SSD and GPU is possible.
| Reconfigurable resources | Total number of resources | performance |
|---|---|---|
| GPU:Nvidia Tesla K20 | 59 | 69.03TFlops |
| SSD:ioDrive2(365GB) | 4 | 1.46TB |
| Storage:PCIe SAS (36TB) | 6 | 216 TB |
Software
VCC in our center has CentOS 6.4 installed as an operating system. Therefore, those who use a Linux-based OS for program development can easily develop and port their programs on this cluster.
At present, the following software is available.
| Software |
|---|
| Intel Compiler (C/C++, Fortran) |
| Intel MPI(Ver.4.0.3) |
| Intel MKL (Ver.10.2) |
| AVS/Express PCE |
| AVS/Express MPE (Ver.8.1) |
| Gaussian09 |
| GROMACS |
| OpenFOAM |
| LAMMPS |
| Programming language |
|---|
| C/C++(Intel Compiler/GNU Compiler) |
| FORTRAN(Intel Compiler/GNU Compiler) |
| Python |
| Octave |
| Julia |
Integrated scheduler composed of Job manipulator and NQSII is used for job management on VCC.
Scheduler
Performance tuning on VCC
Performance tuning on VCC can be categorized roughly into intra-node parallelism (shared-memory parallel processing) and inter-node parallelism (distributed memory parallel processing). The former parallelism distributes the computational workload to 20 cores on a single VCC node, and the latter parallelism to multiple nodes.
To harness the computational performance of the inherent performance of VCC, users need to simultaneously use intra-node and inter-node parallelism. In particular, since VCC has a large number of cores on a single node, intra-node parallelism leveraging 20 cores is efficient and effective in the case where computation is executable within a 64 GB main memory.
Furthermore, further performance tuning is possible by taking advantage of the reconfigurable resources of VCC. For example, the GPU could help gain more computational performance and SSD can help accelerate I/O performance.
Intra-node parallelism (shared-memory parallelism)
The main characteristic of this parallelism is that 20 cores of a single scalar processor “shares” a 64 GB main memory address space. In general, shared memory parallel processing is easier than distributed memory parallel processing in terms of programming and tuning. This is true because VCC and intra-node parallelism are easier than inter-node parallelism.
Representative techniques for Intra-node parallelism on VCC are the “OpenMP” and “pthread”.
The OpenMP defines a set of standard APIs (Application Programming Interfaces) for shared memory parallel processing. The OpenMP targets shared memory architecture systems. For example, as the code below shows, users only have to insert a compiler directive, which is an instruction to the compiler, onto the source code and then compile it. As a result, the compiler automatically generates an execution module which is performed by multiple threads. The OpenMP is a parallel processing technique which beginners of parallel programming can undertake with relative ease. Fortan, C and C++ can be the source code.
More detailed information on the OpenMP can be obtained from books, articles, and the Internet. Please check out these information sources.
Example 1:
#pragma omp parallel
{
#pragma omp for
for(i =1; i < 1000; i=i+1) x[i] = y[i] + z[i]; }
Example 2:
!$omp parallel
!$omp do
do i=1, 1000
x(i) = y(i) + z(i)
enddo
!$omp enddo
!$omp end parallel
More detail information on OpenMP can be obtained from books, documents, the Internet. Please check it out.
A thread is called a lightweight process and a fine-grained unit of execution. By using threads rather than processes on a CPU, the context switch can be executed faster, which will result in the acceleration of computing.
Importantly, in the case of using threads on VCC, users have to declare the use of all CPU cores as follows before submitting a job request:
#PBS -l cpunum_job=20
Internode parallelism (distributed memory parallel processing)
The main characteristic of this parallelism is that it leverages multiple memory address spaces on different nodes rather than on an identical memory address space. This characteristic is the reason why distributed memory parallel processing is more difficult than shared memory parallel processing.
Representative inter-node parallelism on VCC is the MPI (Message Passing Interface).
A Message Passing Interface provides a set of libraries and APIs for distributed parallel programming based on a message-passing method. Based on considerations of communication patterns that will most likely happen on distributed-memory parallel processing environments, the MPI offers intuitive API sets for peer-to-peer communication and collective communications, in which multiple processes are involved, such as MPI_Bcast and MPI_Reduce. Under MPI parallelism, developers must write a source code by considering data movement and workload distribution among MPI processes. Therefore, MPI is a somewhat more difficult parallelism for beginners. However, developers will learn to write a source code that can run faster than the codes with HPF, once they become intermediate and advanced programmers that can write a source code by considering hardware architecture and other characteristics. Furthermore, MPI has become a de facto standard utilized by many computer simulations and analysis. Moreover, today's computer architecture has become increasingly "Clusterized" and thus, mastering MPI is preferred.
Acceleration using GPU
In VCC, 59 NVIDIA Tesla K20 are prepared as reconfigurable resources. For example, by attaching 2 GPUs to each of 4 VCC nodes, users can try acceleration of computational performance using 8 GPUs. CUDA (Compute Unified Device Architecture) is prepared as a development environment in our Center.
More detailed information is available here.
More detail information is available from here.
更新日時:2020年03月15日 / 24-screen Flat Stereo Visualization System
This service ended.
System overview
24-screen Flat Stereo Visualization System is composed of 24 50-inch Full HD (1920x1080) stereo projection module (Barco OLS-521), Image-Processing PC cluster driving visualization processing on 24 screens. A notable feature of this visualization system is that it enables approximately 50 million high-definition stereo display with horizontal 150 degree view angle. Also, it is notable that large-scale and interactive visualization processing becomes possible through the dedicated use of PC cluster for large-scale visualization (VCC).
Furthermore, OptiTrackFlex13, a motion capturing system has been introduced in this visualization system. By making use of the software corresponding to the motion capturing system, interactive visualization leveraging Virtual Reality (VR) becomes possible.
Furthermore, high definition video-conference system (Panasonic KX-VC600) is available.
Node performance
Image Processing PC Cluster on Umemkita (IPC-C) is composed of 7 computing nodes, each of which has two Intel Xeon E5-2640 2.5GHz processors, a 64 GB main memory, 2 TB hard disk (RAID 1), and NVIDIA Quadro K5000. This PC cluster controls visualization processing on 24 screens.
| 1node (IPC-C) | |
|---|---|
| # of processor(core) | 6(12) |
| Main memory | 64 GB |
| Disk | 2TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 1 |
| Performance | GFlops |
System performance
IPC-C is a cluster system which 7 computing nodes are connected on 10GbE. The peak performance of IPC-C is as follows.
| IPC-C | |
|---|---|
| # of processor(core) | 42(84) |
| Main memory | 448GB |
| Disk | 14TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 7個 |
| Performance | Xx GFlops |
Software
IPC-C has Windows 7 Professional and Cent OS 6.4 dual-installed as operating system. Users can select either of operating systems according to their purposes.
The following software are installed on IPC-C.
Visualization software
| AVS Express/MPE VR | General-purpose visualization software. Available for VR display such as CAVE. |
|---|---|
| IDL | Integrated software package including data analysis, visualization, and software development environemnt |
| Gsharp | Graph/contour making tool. |
| SCANDIUM | Image analysis processing of SEM data |
| Umekita | High-quality visualization of stereo structural data from measurement devices such as electron microscope |
VR utility
| CAVELib | APIs for visualization under multi-display and PC cluster |
|---|---|
| EasyVR MH Fusion VR | Software for displaying 3D model in 3D-CAD/CG software on VR display |
| VR4MAX | Software for displaying 3D model on 3ds Max |
更新日時:2019年03月15日 / 15-screen Cylindrical Stereo Visualization System
This service ended.
System Overview
15-screen Cylindrical Stereo Visualization System is a visualization system composed of 15 46-inch WXGA (1366x768) LCD, and Image-Processing PC Cluster driving visualization processing on 15 screens. A notable characteristic of this visualization system is that it enables approximately 16-million-pixel very high-definition stereo display. Also, it is notable that large-scale and interactive visualization processing becomes possible through the dedicated use of PC cluster for large-scale visualization (VCC).
Furthermore, OptiTrackFlex13, a motion capturing system has been introduced in this visualization system. By making use of the software corresponding to the motion capturing system, interactive visualization leveraging Virtual Reality (VR) becomes possible.
Furthermore, high definition video-conference system (Panasonic KX-VC600) is available.
The install location of this visualization system is Umekita Office of the Cybermedia Center, Osaka University ( Grand Front Osaka Tower C 9th Floor)
Node performance
Image Processing PC Cluster on Umemkita (IPC-U) is composed of 6 computing nodes, each of which has two Intel Xeon E5-2640 2.5GHz processors, a 64 GB main memory, 2 TB hard disk (RAID 1), and NVIDIA Quadro K5000. This PC cluster controls visualization processing on 15 screens.
| 1 node (IPC-U) | |
|---|---|
| # of processor(core) | 2(12) |
| Main memory | 64 GB |
| Disk | 2 TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 1 |
| Performance | 240 GFlops |
System performance
IPC-U is a cluster system which 6 computing nodes are connected on 10GbE. The peak performance of IPC-U is as follows
| IPC-U | |
|---|---|
| # of processor(core) | 12(72) |
| Main memory | 384 GB |
| Disk | 12 TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 6 |
| Performance | 1.44 TFlops |
Software
IPC-U has Windows 7 Professional and Cent OS 6.4 dual-installed as operating system. Users can select either of operating systems according to their purposes.
The following software are installed on IPC-U.
Visualization software
| AVS Express/MPE VR | General-purpose visualization software. Available for VR display such as CAVE. |
|---|---|
| IDL | integrated software package including data analysis, visualization, and software development environemnt |
| Gsharp | Graph/contour making tool. |
| SCANDIUM | Image analysis processing of SEM data |
| Umekita | High-quality visualization of stereo structural data from measurement devices such as electron microscope |
VR utility
更新日時:2014年10月14日 / HCC
HCC system will be retired on September 30, 2017. Please be aware of and ready for system retirement.
System overview
HCC is a cluster system composed of virtual linux machines' 579 nodes. We have provided this system since October 2012.
Express5800/53Xh は CPUがIntel Xeon E3-1225v2(1CPU 4コア)、メモリが8GB/16GBの性能を持ちますが、仮想Linuxでは 2コア、4GB/12GB が利用可能です。仮想LinuxのOSはCent OS 6.1、Intel製の C/C++ 及び Fortran コンパイラを導入しています。また、Intel MPI ライブラリーを用いたMPI 並列計算が可能です。
システム性能
| 豊中地区 | 吹田地区 | 箕面地区 | ||||
|---|---|---|---|---|---|---|
| ノード毎 | 総合 | ノード毎 | 総合 | ノード毎 | 総合 | |
| プロセッサ数 | 2 | 536 | 2 | 338 | 2 | 276 |
| 演算性能 | 28.8 GFLOPS | 7.7 TFLOPS | 28.8 GFLOPS | 4.9 TFLOPS | 28.8 GFLOPS | 4.0 TFLOPS |
| 主記憶容量 | 4GB | 1.1TB | 4/12GB | 1.2TB | 4GB | 0.6TB |
| ノード数 | 268ノード | 169ノード | 138ノード | |||
| 全ノード数 | 575ノード | |||||
※ 3地区に分散して設置しています。
汎用コンクラスタ(HCC)利用における注意事項
ホストOSを学生教育用の端末PCとして利用している関係上、突然のノード停止が発生する可能性があります。この停止は事前に予測できずに発生いたしますので、投入されたバッチリクエストの動作に影響する可能性があることをご了承ください。
※ 実行中のバッチリクエストは自動的に再スケジューリングされます。また、長時間、大規模並列のバッチリクエストを実行されると、ノードの停止の影響を受けやすくなりますので、ご注意ください。
※ メンテナンスの為、2週間毎に各ジョブクラスを1日サービス停止します。そのため、経過時間は最大12~13日までとなります。
※ それ以上の日数を指定するとバッチリクエストが全く実行されませんのでご注意ください。メンテナンスによるサービス停止日については、年間スケジュールをご参照ください。
※ 利用できるノード数や経過時間の制限については ジョブクラス表 をご参照ください。
更新日時:2014年08月14日 / SX-9
This service ended. Please use the successor machine, SX-ACE.
SX-9のCPUはプロセッサ当たり102.4GFLOPSの性能を持ち、各ノードには16個を搭載、ノード毎の演算性能は1.6TFLOPS、主記憶容量は1TBを有します。
10ノードの総合演算性能は16TFLOPS、総合メモリは10TBの大規模システムになり、MPIを用いた並列処理により最高で8ノード(12.8TFLPS, 8TBメモリ)の演算が可能です。
更新日時:2014年07月14日 / SX-8R
This service ended. Please use the successor machine, SX-ACE.
SX-8Rは、大容量メモリ型(DDR2)8ノードと高速メモリ型(FC-RAM)12ノードの2種類の機種から構成されます。各ノードには8個のCPUを搭載し、ノード毎の演算性能は大容量メモリ型が281.6GFLOPS、高速メモリ型が256GFLOPSとなっています。
また、主記憶容量は大容量メモリ型が256GB、高速メモリ型は4ノードが64GB、8ノードが128GBとなっています。
大容量メモリ型の8ノードは、ノード間接続装置(IXS)で接続され、MPIプログラミングにより最大2TBメモリの演算が可能です。
更新日時:2014年04月14日 / PCC
This service ended. Thank you for your use.
Express5800/120Rg-1×128台でPCクラスタシステムとして演算サービスを提供しています。
Express5800/120Rg-1 は CPU が Intel Xeon 3GHz (Woodcrest) 2CPU 4コア、メモリが 16GB の性能を持ちます。
OS は SUSE Linux Enterprise Server 10、Intel 製の C/C++ 及び Fortran コンパイラを導入しています。
また、MPI-CH 1.2.7p1 及び Intel MPI ライブラリー を用いた MPI 並列演算が可能です。
更新日時:2007年01月19日 / SX-5
本システムの提供は終了しました。(提供期間:2001年1月-2007年1月)
SX-5/128M8は16個のベクトルプロセッサと128GBの主記憶を搭載したNEC SX-5/16Afの8ノードと、64Gbpsの専用ノード間接続装置IXS、800MbpsのHiPPIおよび1GbosのGigabit Ethernetによって接続したクラスタ型スーパーコンピューティングシステムです。
システム全体の仕様
| 理論演算性能 | 1.2 TFLOPS |
|---|---|
| ノード数 | 8 |
| CPU数 | 128 |
| 定格消費電力 | 443.36 kVA |
1ノードあたりの仕様
| CPU | NEC SX-5/16Af |
|---|---|
| CPU数 | 16 |
| メモリ容量 | 128 GB |
| メモリ帯域 | 16 GB/s |
| 理論演算性能 | 160 GFLOPS |
| 定格消費電力 | 55.42 kVA |
