Captionから高解像・多フレームな動画を生成するための深層学習モデルの改良に関する研究
氏名:村田征矢1、李天鎬2
所属:1 大阪大学大学院情報科学研究科マルチメディア工学専攻、2 大阪大学サイバーメディアセンター先進高性能計算機システムアーキテクチャ共同研究部門
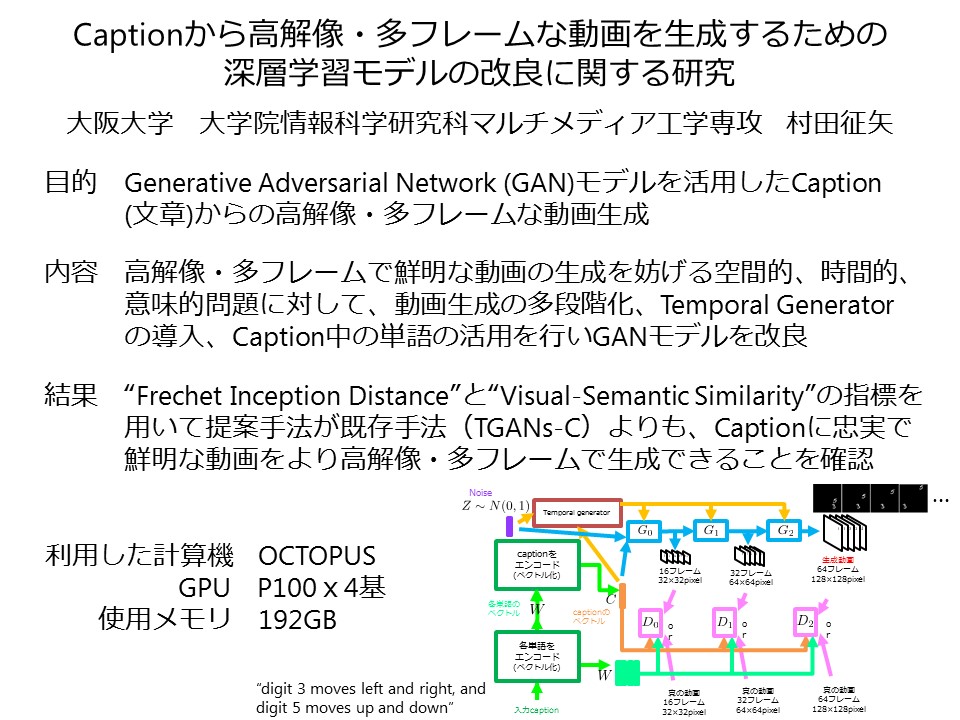
概要:Generative Adversarial Network (GAN)モデルを活用したCaption(文章)からの高解像・多フレームな動画を生成する時に生じる空間的、時間的、意味的問題に対して、動画生成の多段階化、Temporal Generatorの導入、Caption中の単語の活用を行いGANモデルを改良した.提案手法が既存手法(TGANs-C)よりも、Captionに忠実で鮮明な動画をより高解像・多フレームで生成できることを確認した.
Posted : 2019年03月01日
