SQUID GPUノードにおけるGPU間集団通信性能の分析
氏名:高橋慧智
所属:大阪大学 D3センター
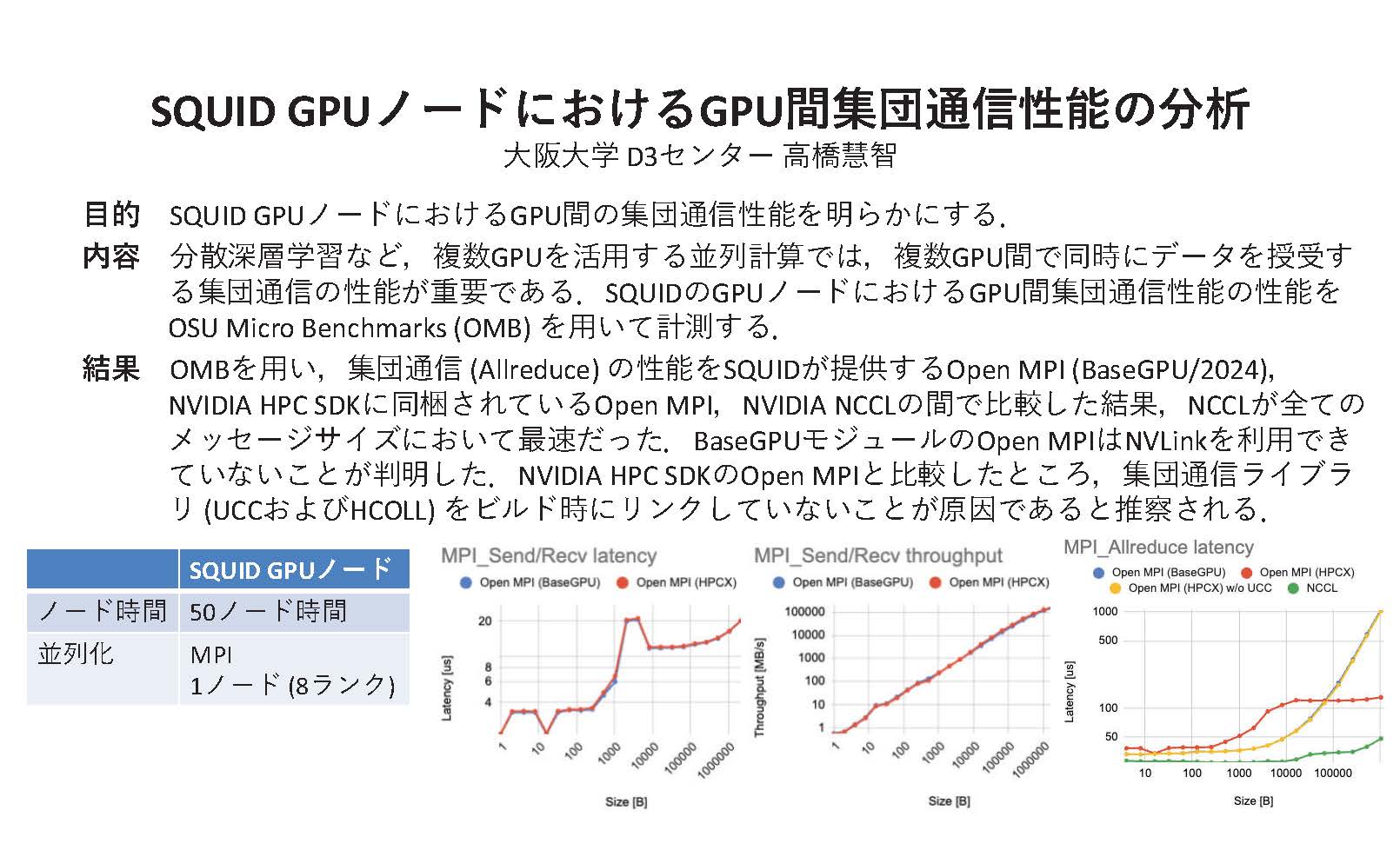
概要:SQUID GPUノードにおけるGPU間集団通信性能を明らかにすることを目的とし、OSU MicroBenchmarks (OMB) を用いてAllreduceの性能を評価した。SQUID標準のOpen MPI(BaseGPU/2024)、NVIDIA HPC SDK同梱のOpen MPI、NVIDIA NCCLを比較した結果、NCCLが全メッセージサイズで最速であった。BaseGPUモジュールのOpen MPIはNVLinkを利用できておらず、NVIDIA HPC SDKのOpen MPIとは集団通信ライブラリ(UCCやHCOLL)のリンク有無が性能差の要因と推察される。
Posted : 2025年03月31日
