2024.04.18
The maximum memory usage per generic CPU node can be collected by periodically executing "qstat -Jf".
Of the memory cgroup size (Memory Cgroup Resources) used by the job with "qstat -Jf", "Memory Usage" is the current memory usage and "Max Memory Usage" is the maximum memory usage.
2022.12.09
Yes, you can install OpenMPI. In the case, you have to make module file as the following:
|
|
#%Module 1.0 # # OMP-sample # proc ModulesHelp { } { puts stderr "OMP-sample\n" } prepend-path PATH /sqfs/work/(your installed path)/bin prepend-path LD_LIBRARY_PATH /sqfs/work/(your installed path)/lib/ setenv MPI_ROOT /sqfs/work/(your installed path)/ |
You specify module file in job script as the following:
|
|
#PBS -T openmpi #PBS -v NQSV_MPI_MODULE=module file PATH |
2022.10.13
You can install wandb with pip command.
pip install wandb
wandb login "XXXX"
SQUID can not access to internet on computational nodes, however, we permitted only for "wandb".
Please describe a job script file as the following:
#!/bin/bash
#PBS -q SQUID
#PBS --group=[group name]
#PBS -l elapstim_req=1:00:00
cd $PBS_O_WORKDIR
export http_proxy="http://ibgw1f-ib0:3128"
export https_proxy="http://ibgw1f-ib0:3128"
python test.py
Please use requests-2.24. Versions such as 2.26 will not work properly with SQUID.
2022.01.18
In OCTOPUS and SQUID, the machinefile is automatically generated and set to MPI based on the value specified by PBS -l cpunum_job using the environment variable $NQSII_MPIOPTS / $NQSV_MPIOPT. Options such as ppn, rr, and prehost cannot be specified at the same time as the machinefile.
Even if we assume that we allocate 128 MPI processes / 64 processes per node, and specify them as follows, the ppn option will be invalid:
mpirun ${NQSV_MPIOPTS} -np 128 -ppn 64 ./a.out
Basically, 128 MPI processes can be created and 64 processes can be allocated per node by specifying the following.
#PBS -l cpunum_job=64
(...)
mpirun ${NQSV_MPIOPTS} -np 128 ./a.out
The environment variable $NQSV_MPIOPTS specifies the following options and files.
-machinefile /var/opt/nec/nqsv/jsv/jobfile/[a number of requestID and etc.]/mpinodes
The mpinodes file is a machine file, and in the above case, the host name and number of cores are specified as follows.
host001:64
host002:64
However, if you want to specify the process placement more precisely (e.g., if you want to set up pinning and compute without using processes on specific cores), the above options may not work in some cases. When using ppn, rr, and prehost options, specify the hostfile option and $PBS_NODEFILE environment variable instead of $NQSII_MPIOPTS / $NQSV_MPIOPT. 128 To create MPI processes and allocate 64 processes per node, specify as follows.
mpirun -hostfile ${PBS_NODEFILE} -np 128 -ppn 64 ./a.out
If you use PBS_NODEFILE, the value specified by #PBS -l cpunum_job will not be set to MPI. Please check the number of processes by yourself.
2019.12.05
If your file name includes a sequential number, you can do it with a "parametric job" on our system.
An environmental value "$PBS_$SUBREQNO" store a sequential number that you specified with "qsub -t" option (1 - 5 number in the following example).
When you submit a "parametric job", our system receives a few jobs (5 jobs in the following example) set different input files per job (input1 - input5 in the following example).
example: job script file
|
|
#PBS -q OCTOPUS #PBS -l elapstim_req=0:30:00,cpunum_job=24 cd $PBS_O_WORKDIR ./a.out input$PBS_SUBREQNO |
example: how to submit a job
example: qstat result: in the case of a "parametric job", qstat display one record per one qsub
|
|
RequestID ReqName UserName Queue Pri STT S Memory CPU Elapse R H M Jobs --------------- -------- -------- -------- ---- --- - -------- -------- -------- - - - ---- 123456[].oct nqs username OC1C 0 QUE - - - - Y Y Y 1 |
example: sstat result: in the case of "parametric job", sstat display record as much as a number that you specified with "qsub -t" option
|
|
RequestID ReqName UserName Queue Pri STT PlannedStartTime --------------- -------- -------- -------- ----------------- --- ------------------- 123456[1].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[2].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[3].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[4].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[5].oct nqs username OC1C 0.5002/ 0.5002 QUE - |
2019.04.11
If you did not specify "${NQSII_MPIOPTS}" when you execute MPI program, you will get the following error message:
[mpiexec@oct-***] HYDT_bscd_pbs_query_node_list (../../tools/bootstrap/external/pbs_query_node_list.c:23): No PBS nodefile found
[mpiexec@oct-***] HYDT_bsci_query_node_list (../../tools/bootstrap/src/bsci_query_node_list.c:19): RMK returned error while querying node list
[mpiexec@oct-***] main (../../ui/mpich/mpiexec.c:621): unable to query the RMK for a node list
Please see the following page about a sample job script for MPI program:
How to use Intel MPI on OCTOPUS
This error message notice that "nodefile" for MPI program does not exist. "nodefile" automatically is set by ${NQSII_MPIOPTS} on OCTOPUS.
2019.04.11
If our system resource is not crowded, you can run some jobs at the same time with the following procedure.
qsub A.nqs
qsub B.nqs
2019.01.10
Binary data is seldom written in an output file when each process is written to output data to the same name file.
Please use MPI-IO or write to output data to separate files for each process.
Please see the following page for MPI-IO
MPIの実行結果を1つのファイルに出力したい
2017.06.06
No, you can't. Our scheduler will choose appropriated node on automatically for your job.
Thank you for your understanding.
2017.05.29
When you specified OpenMP or Auto-Parallelization option on compile, the compiler links the library for parallelization whether parallel directive or not.
The functions of library for Parallelization differ from the normal functions in that have the lock routine for that other thread limit access to resources.
If it calls the functions of Library for parallelization on the un-parallelization part, it runs on one thread, of course. Therefore, it will not wait for other processes for lock routine. But, it needs a little bit processing time. Because the functions of library for parallelization have to make a decision for whether should do or do not the lock routine. Please note that.
2017.01.20
If you want to re-direct standard output of MPI result on vector node of SQUID, please use the script "/opt/nec/ve/bin/mpisep.sh".
How to use this script is the following:
|
|
#PBS -v MPISEPSELECT=3 mpirun -np 160 /opt/nec/ve/bin/mpisep.sh ./a.out |
In the case, the standard output is output to stdout.0:(MPI process ID), and the standard error output is output to stderr.0:(MPI process ID) in real time.
Please see "3.3" of the following manual about the detail:
NEC MPI User's guide
If you modified mpisep.sh, you change stdout/stderr filename into whatever you want to name.
2016.08.24
If you install any library and application to your disk, our permits are not necessary.
If you expect that center install any library and application to a whole of system, please contact us from the following web form:
Inquiry / Request form
Please note that we may not permit or we may ask to install with yourself, depending on the kind of library and application.
2016.08.24
Yes. We provide Python on all system.
2016.08.24
Yes. You can do it by "Workflow" or "Request Connection Function".
Please see the following manual 7.Workflow and 1.2.22. Request Connection Function about how to use.
NQSII User's Guide
The difference between Workflow and Request Connection Function
The difference is the timing of running request. In the case of Workflow, all request become an object for assign immediately after submitting. In the case of Request Connection Function, next request become an object for assign after the previous request finished . Therefore, you should choose the workflow, if system is crowded.
2016.08.24
You can specify for MPI slave node almost all environment value by "#PBS -v option". But you can not specify some environment value on NQSII. Path is one of those. Please see the following manual, the end of 1.16.qsub(1).
NQSII User's Guide
You can specify PATH for slave node by the MPI runtime option.
2015.03.04
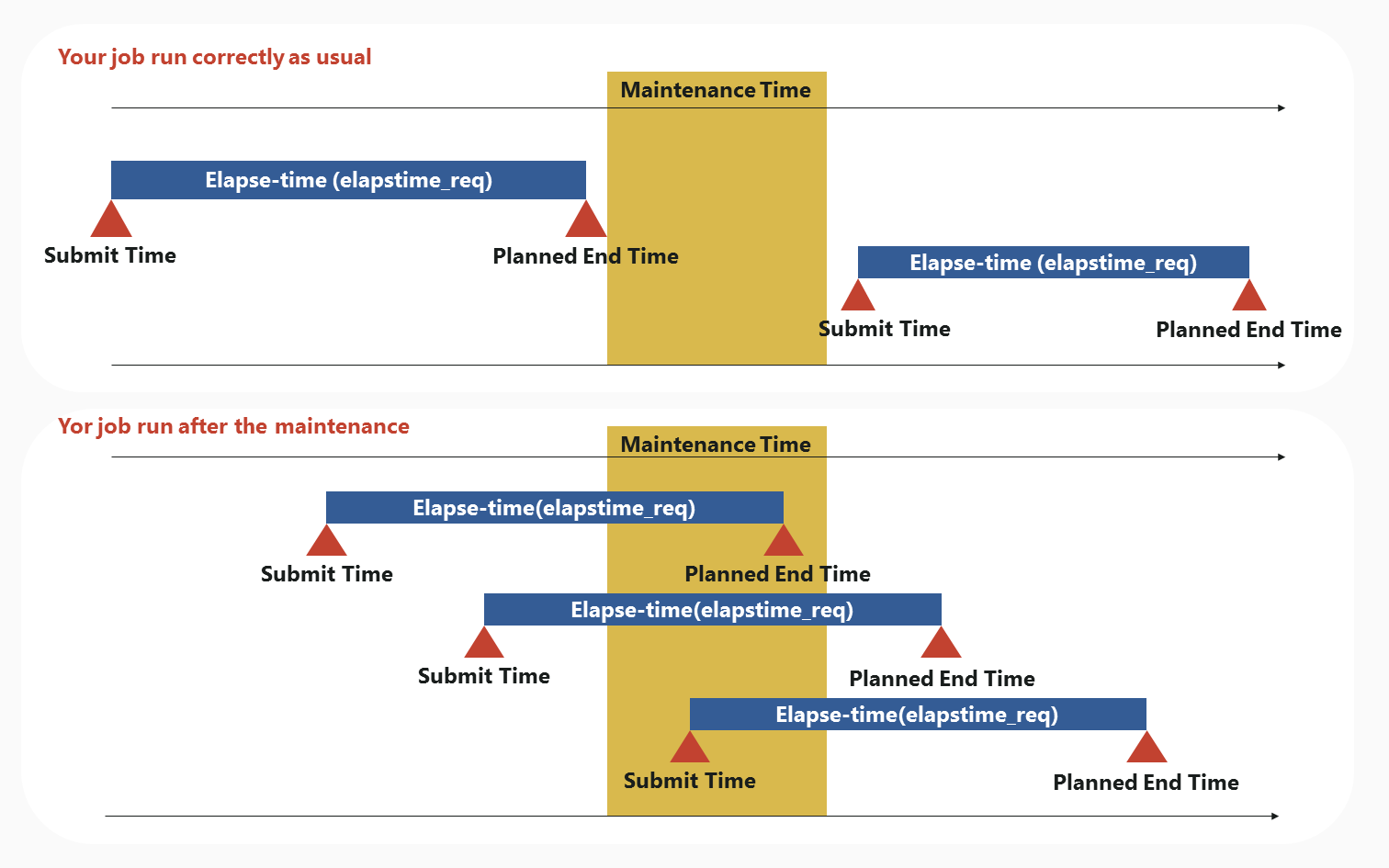
Basically, the job will run correctly. But that action differs depending on your submitted time or your specified elapse-time.
* Please note that your job might not run depending on situation of jobs the other users submitted, in the case of shared use.
Please see the following about the detail.
If you submitted a job before the maintenance
If Planned End Time of your submitted job exceed the beginning time of the maintenance, your job will not run till the maintenance finished. Planned End Time is calculated from submit-time and elapse-time which you specified elapstim_req at job-script.
For example, if you specified "elapstime_req=5:00:00" at your job-script and you submitted your job on 1:00 p.m., Planned End Time become 6:00 p.m.
* Without depending on the above, please note that your job might not run depending on situation of jobs the other users submitted, in the case of shared use.
If Planned End Time of your submitted job doesn't exceed the beginning time of the maintenance
Your job will run correctly without waiting the maintenance finished.
If Planned End Time of your submitted job exceed the beginning time of the maintenance
As mentioned above, your job will not run till the maintenance finished. The submitted job is received as QUE status, and will run after the maintenance except the maintenance held in the end of the fiscal year. All jobs will be deleted in the maintenance held in the end of the fiscal year. If you re-adjust the elapsed-time (elapstime_req) so as not to exceed the beginning time of maintenance and if re-submit, your job might be run soon. When you are in a hurry, please try it.
From before planning the maintenance, if you have ran the job that Planned End Time exceed the beginning time of the maintenance
Maybe this situation will be in the case of dedicated use only. Your job will run correctly till the beginning maintenance. We're afraid that you must stop during the maintenance. If your job corresponds to this situation, we would contact you.
If you submit a job during the maintenance
Your job will not run till the maintenance finished. The submitted job is received as QUE status, and will run after the maintenance.
If you submit a job after the maintenance
Your job will run correctly.
2014.12.11
You have to migrate from SX-ACE to SX-Aurora TSUBASA according to the following procedure:
migration procedure
2014.12.11
Yes.
When you outputted the binary data on SX-9 with unformatted WRITE statement,etc, SX-ACE can read this binary data.
2014.07.14
「qwait」コマンドを使用することで、実現可能です。
このコマンドは引数で与えたリクエストID(例:12345.cmc)を待ち合わせするというものです。
指定のリクエストIDのジョブが終了するとメッセージ終了と共にコマンドが終了します。
コマンドの詳細についてはポータルで公開されておりますマニュアル
「NQS利用の手引」のリファレンス編 第1章 ユーザコマンドをご参照頂けますようお願い致します。
NQSII利用の手引き(要認証)
NQSV利用の手引き
※ man qwait でもヘルプを参照できます。
qwait については下記のような使い方が可能です。
監視スクリプトをバックグラウンド実行し、スクリプト内で qwaitを実行します。
exitコード(上記のマニュアルに記載があります)で判定し、その後の動作を分岐させています。
参考にしてください。
-----------
$ qsub job1-1
Request 12345.cmc submitted to queue: Pxx.
$ (./chkjob >& log &)
----- chkjob
#!/bin/sh
while :
do
qwait 12345.cmc #リクエストIDを任意のものに変更して下さい
case $? in
0) qsub job1-2;exit;;
1) qsub job2-1;exit;;
2) qsub job3-1;exit;;
3) echo NQS error | mail xxxx@yyyy.ac.jp;exit;;#メールアドレスを任意のものに変更してください
7) continue;;
*) ;;
esac
done
------------
以上です。
