2024.04.23
特定のサブルーチンに対してVH CALLを使用することで、VHでの計算が可能です。詳細な手順は以下のAurora Forumに掲載しておりますので、ご一読ください。
libvhcall-fortran
動作確認を実施いただくための簡易プログラムを以下に用意しております。
VH CALL動作確認用プログラム
コンパイル方法
module load BaseVEC/2024
sh comp.sh
投入方法(投入前にrun.shを編集しgroupの指定を変更してください)
qsub run.sh
2024.04.18
汎用CPUノード単位の最大メモリ使用量は「qstat -Jf」を定期的に実行することで採取可能です。
qstat -Jf でジョブが使用しているメモリcgroupサイズ(Memory Cgroup Resources)のうち、「Memory Usage」が現在のメモリ使用量、「Max Memory Usage」が最大メモリ使用量を表しています。
2022.12.09
OpenMPIについては独自にインストールしてご利用することが可能です。
MPIのパスを記載したmoduleファイルを作成してください。
|
|
#%Module 1.0 # # OMP-sample # proc ModulesHelp { } { puts stderr "OMP-sample\n" } prepend-path PATH /sqfs/work/(MPIインストール先)/bin prepend-path LD_LIBRARY_PATH /sqfs/work/(MPIインストール先)//lib/ setenv MPI_ROOT /sqfs/work/(MPIインストール先)/ |
ジョブスクリプトの中で以下のようにmoduleファイル指定してください。
|
|
#PBS -T openmpi #PBS -v NQSV_MPI_MODULE=moduleファイルへの(フルパス) |
2022.10.13
wandbについてはpipコマンドにてインストール可能です。
pip install wandb
wandb login "XXXX"
SQUIDでは原則計算ノードからのインターネットアクセスを許可しておりませんが、wandbに限定して許可しています。
以下のようにジョブスクリプトを記述してください。
#!/bin/bash
#PBS -q SQUID
#PBS --group=[グループ名]
#PBS -l elapstim_req=1:00:00
cd $PBS_O_WORKDIR
export http_proxy="http://ibgw1f-ib0:3128"
export https_proxy="http://ibgw1f-ib0:3128"
python test.py
requests-2.24を使用してください。2.26等のバージョンについては、SQUIDで正常に動作しません。
2022.01.18
SQUIDでは環境変数 $NQSII_MPIOPTS / $NQSV_MPIOPTによって、#PBS -l cpunum_jobで指定した値を元に、machinefileを自動生成しMPIに設定しています。ppn, rr, prehostといったオプションはmachinefileと同時に指定することが出来ないため、仮に128 MPIプロセス / 1ノードあたり64プロセス割り当てることを想定し、以下のように指定したとしても、ppn オプションは無効となります。
mpirun ${NQSV_MPIOPTS} -np 128 -ppn 64 ./a.out
基本的には以下のように指定いただくことで、128 MPIプロセスを生成し、1ノードあたり64プロセス割り当てることが可能です。
#PBS -l cpunum_job=64
(中略)
mpirun ${NQSV_MPIOPTS} -np 128 ./a.out
環境変数 $NQSV_MPIOPTS は、以下のオプションとファイルが指定されています。
-machinefile /var/opt/nec/nqsv/jsv/jobfile/[リクエストID等の数値]/mpinodes
mpinodesファイルはマシンファイルとなっており、上記の場合は以下のようなホスト名、コア数が指定されています。
host001:64
host002:64
ただし、より細かくプロセス配置を指定したい場合(例えばピニングを設定し特定のコアにプロセスを使用せずに計算する場合など)上記のオプションでは対応出来ないケースがあります。ppn, rr, prehostオプションを使用する場合は、環境変数 $NQSII_MPIOPTS / $NQSV_MPIOPT を指定する代わりにhostfileオプションと環境変数 $PBS_NODEFILE を指定してください。128 MPIプロセスを生成し、1ノードあたり64プロセス割り当てる場合は以下のように指定します。
mpirun -hostfile ${PBS_NODEFILE} -np 128 -ppn 64 ./a.out
※PBS_NODEFILEを使う場合、#PBS -l cpunum_jobで指定した値がMPIに設定されません。ご自身でプロセス数の確認をお願いします。また、OCTOPUSではご利用いただけません。
2021.11.26
以下のコマンドで取得可能です。ジョブスクリプトの最後で実行してください。
$ nvidia-smi --query-accounted-apps=timestamp,gpu_name,gpu_bus_id,gpu_serial,gpu_uuid,vgpu_instance,pid,time,gpu_util,mem_util,max_memory_usage --format=csv
出力例は以下のとおりです。最後に記載されている523MiBがGPUで使用した最大メモリサイズです。
2021/11/24 19:26:26.333, A100-SXM4-40GB, 00000000:27:00.0, 1564720026417, GPU-a3b25bed-7bb1-cbd8-89e3-3f14b6118874, N/A, 761279, 117202 ms, 2 %, 0 %, 523 MiB
ジョブクラス「SQUID-S」を使用している場合は、同じノード内で別の方のジョブが実行されている場合があるため、正しい値が取得されない可能性があります。予めご了承ください。
2021.11.08
ご自身でインストールすることで、利用可能です。手順は以下のとおりです。
python venvを使用する
インストール手順
|
|
# Python+GPUのEnvironmental modulesを設定する module load BasePy module --force switch python3/3.6 python3/3.6.GPU module load BaseGPU module load cudnn/8.2.0.53 #Pytorchをインストールする仮想環境 test-envを作成し、Activateする python3 -m venv /sqfs/work/【グループ名】/【ユーザ名】/test-env/ source /sqfs/work/【グループ名】/【ユーザ名】/test-env/bin/activate # SQUIDのGPUノード(A100)に対応するCUDA11.1 + Pytorchをインストール pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html |
利用手順(ジョブスクリプト例)
|
|
#!/bin/bash #PBS -q SQUID #PBS --group=(グループ名) #PBS -l elapstim_req=1:00:00,gpunum_job=8 cd $PBS_O_WORKDIR module load BasePy module --force switch python3/3.6 python3/3.6.GPU module load BaseGPU module load cudnn/8.2.0.53 source /sqfs/work/【グループ名】/【ユーザ名】/test-env/bin/activate python test.py |
mini-forgeを使用する
まず以下のページを参考にminiforgeをインストールしてください。
miniforgeのインストール・使い方(SQUID)
次に、以下を参考にPytorchをインストールしてください
|
|
# miniforge仮想環境の作成準備 conda config --add envs_dirs /sqfs/work/(グループ名)/(利用者番号)/conda_env conda config --add pkgs_dirs /sqfs/work/(グループ名)/(利用者番号)/conda_pkg #Pytorchをインストールする仮想環境 test-envを作成し、Activateする conda create --name test-env python=3.8 conda activate test-env # SQUIDのGPUノード(A100)に対応するCUDA11.1 + Pytorchをインストール conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge |
1ノードでの利用手順(ジョブスクリプト例)
|
|
#!/bin/bash #PBS -q SQUID #PBS --group=(グループ名) #PBS -l elapstim_req=1:00:00,gpunum_job=8 cd $PBS_O_WORKDIR conda activate test-env python test.py |
2ノードでの利用手順(ジョブスクリプト例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/bin/bash #PBS -q SQUID #PBS --group=(グループ名) #PBS -b 2 #PBS -l gpunum_job=8 #PBS -l elapstim_req=01:00:00 cd $PBS_O_WORKDIR source ~/.bashrc conda activate test-env echo "===================" MASTER_NODE=`head -1 ${PBS_NODEFILE}` USE_PORT=12321 HOSTNAME=`hostname -s` echo "-------------------" echo "HOSTNAME =[${HOSTNAME}] MASTER_NODE=[${MASTER_NODE}] USE_PORT=[${USE_PORT}]" echo "===================" python -m torch.distributed.launch --nnodes=2 --nproc-per-node=8 --rdzv-id=100 --rdzv-backend=c10d --rdzv-endpoint=${MASTER_NODE}:${USE_PORT} test.py |
2021.10.11
ワークフローにてA⇒Bの順序で制御しているときに、AがRERUNとなった場合、Aを再実行、Bは再スケジューリングされ、ワークフローの順番を保ったまま実行されます。
2019.12.05
ファイル名に連続した数値が含まれている場合、パラメトリックジョブという投入方法で、一度に大量のジョブを投入できます。
パラメトリックジョブでは、ジョブスクリプト内の"$PBS_SUBREQNO"環境変数に、-tで指定した数値(下記の例では1から5までの数値)が格納されます。
qsubすると同時に5本のジョブが投入され、a.outに対してそれぞれ異なる入力ファイル(下記の例ではinput1からinput5)が設定されます。
ジョブスクリプト例
|
|
#PBS -q OCTOPUS #PBS -l elapstim_req=0:30:00,cpunum_job=24 cd $PBS_O_WORKDIR ./a.out input$PBS_SUBREQNO |
投入例
qstatの表示例:パラメトリックジョブの場合、1回のqsubにつき1件分の表示となります
|
|
RequestID ReqName UserName Queue Pri STT S Memory CPU Elapse R H M Jobs --------------- -------- -------- -------- ---- --- - -------- -------- -------- - - - ---- 123456[].oct nqs username OC1C 0 QUE - - - - Y Y Y 1 |
sstatの表示例:-tで指定した数値分だけ表示されます
|
|
RequestID ReqName UserName Queue Pri STT PlannedStartTime --------------- -------- -------- -------- ----------------- --- ------------------- 123456[1].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[2].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[3].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[4].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[5].oct nqs username OC1C 0.5002/ 0.5002 QUE - |
2019.04.11
MPIプログラム実行時に${NQSII_MPIOPTS}を指定していなかった場合、以下のようなエラーが出力されます。
[mpiexec@oct-***] HYDT_bscd_pbs_query_node_list (../../tools/bootstrap/external/pbs_query_node_list.c:23): No PBS nodefile found
[mpiexec@oct-***] HYDT_bsci_query_node_list (../../tools/bootstrap/src/bsci_query_node_list.c:19): RMK returned error while querying node list
[mpiexec@oct-***] main (../../ui/mpich/mpiexec.c:621): unable to query the RMK for a node list
以下のページに、MPIプログラムを実行する際のジョブスクリプトの例を掲載しておりますので、まずご参照ください。
OCTOPUSでのintel MPI実行方法
エラーメッセージ自体は、MPIプログラムの"nodefile"(実行する計算ノードを指定する設定ファイル)が存在しないことを通知しています。OCTOPUSでは、${NQSII_MPIOPTS}を指定いただくことで、自動的に設定されます。
2019.04.11
資源に空きがある限り、複数のジョブを同時に実行可能です。
qsub A.nqs
qsub B.nqs
といったように、1件1件個別にqsubしていくことで、A.nqsとB.nqsが同時に実行可能な状態となります。
2019.01.10
MPI並列実行を行うプログラムで各プロセスが同名ファイルにデータを出力するよう記述していると、バイナリが書き込まれてしまう場合があります。
大規模計算機システムのような共有ファイルシステムにおいて各プロセスが同名のファイルにデータを出力することは、各プロセスが同一のファイルにデータを出力することと同じであるため、プロセス間で競合が発生した際にデータが破損してしまい、バイナリデータが書き込まれてしまうことがあります。各プロセスごとに別名のファイルに出力するか、MPI-IOというMPI用の入出力インターフェースを利用することで、プロセス間の競合を防ぐことが可能です。
MPI-IOについては下記をご覧ください。
MPIの実行結果を1つのファイルに出力したい
2017.06.06
計算に使用するノードは、スケジューラ側が自動で最適なノードを割り当てるようになっており、利用者様の方では指定することはできません。
ご理解くださいませ。
2017.05.29
コンパイル時に、OpenMPや自動並列化を使用するオプションを指定した場合、並列化指示行の有無に関わらず、「並列版ライブラリ」がリンクされます。「並列版ライブラリ」の関数(並列版の関数)には通常版ライブラリと比べて、排他制御のために他スレッドのリソースへのアクセスを制限する「ロック処理」が組み込まれています。
並列化指示行を挿入していない箇所で並列版の関数がコールされた場合、1スレッドで動作するので、実際にロック処理に伴う「他スレッドの処理待ち」が発生するわけではないのですが、例えば、「排他が必要かどうか」といった判定を行う都合で、わずかですが通常版ライブラリより処理時間が増えることとなります。
一回のオーバヘッドはわずかですが、大量にコールすると、処理時間に大きく影響することとなります。
ご注意ください。
2017.05.19
MPIを用いた場合、通常は各プロセスごとに出力ファイルが生成されます。しかしMPI-IOを用いて出力先を指定することで、各プロセスの出力を1つのファイルにまとめることができます。
基本的な利用方法
MPI-IOはMPIプログラミングを行うことを前提としています。MPIの基本的な利用方法やコマンドについてはこちらをご覧ください。
以下にfortranで書かれたプログラムを紹介します。こちらを参考に説明します。
ファイルへの出力(書き込み)
各プロセスごとにプロセスID(rank)を取得し、output.datの任意の位置に出力するプログラムです。
たとえば自身のプロセスIDが4の場合、output.datの16-19バイト目(INTEGER換算で5番目)に自身のプロセスIDを書き込みます。
|
|
program sample include 'mpif.h' !! MPI用のインクルードファイル(必ず指定) integer ierr,myrank integer (kind=mpi_offset_kind) idisp call MPI_INIT(ierr) !! MPI並列 開始 call MPI_COMM_RANK(mpi_comm_world,myrank,ierr) !!プロセスID(rank)の取得 idisp=0+4*myrank call mpi_file_open(mpi_comm_world,'output.dat',mpi_mode_rdwr+mpi_mode_create,mpi_info_null,ifh,ierr) call mpi_file_set_view(ifh,idisp,mpi_integer,mpi_integer,'native',mpi_info_null,ierr) call mpi_file_write(ifh,myrank,1,mpi_integer,mpi_status_ignore,ierr) call mpi_file_close(ifh,ierr) call MPI_FINALIZE(ierr) !! MPI並列 ここまで stop end |
プログラムのハイライト部分(8行目-11行目)が、MPI-IOプログラムになります。また7行目は直接MPI-IOに関係があるわけではないですが、9行目でコマンドに引数として渡す変数を設定している部分になりますので、必要な処理になります。
2行目、6行目-7行目、13行目はMPIでの処理を行うためのプログラムです。こちらについてはMPI利用方法(VCC)のページで解説を行っていますのでそちらを参考にしてください。
以下で8行目-11行目のコマンドについて詳しく説明していきます。
mpi_file_open
mpi_file_open(comm, filename, amode, info, fh, ierr)
MPI-IOでの入出力先のファイルをオープンするためのコマンドです。
MPI-IOを行う場合は最初にcallする必要があります。
| 引数 |
| comm |
コミュニケータを指定します。通常はMPI全プロセスをあらわす「MPI_COMM_WORLD」を指定することが多いです。 |
| filename |
入出力先のファイル名を指定します。 |
| amode |
アクセスモードの設定をします。「|」をはさむことで複数同時に指定することが可能です。代表的なものをいくつか紹介します。
mpi_mode_rdonly:読み込みのみ可能
mpi_mode_wronly:書き込みのみ可能
mpi_mode_rdwr :読み書き両方可能
mpi_mode_create:filenameで指定した名前のファイルがない場合、自動で作成
mpi_mode_excl :filenameで指定した名前のファイルがすでに存在する場合、エラーを返す
これ以外にも様々なモードが存在します。
|
| info |
入出力先のファイル情報を設定できますが、基本的には何も渡さない「mpi_info_null」で問題ありません。 |
| fh |
ファイルハンドルです。これ以降filenameで指定したファイルは、fhで指定したファイルハンドルで指定することになります。 |
| ierr |
正常終了時に0が格納されます。エラー時はそれ以外の値が格納されます。 |
mpi_file_set_view
mpi_file_set_view(fh, disp, etype, ftype, datarep, info, ierr)
各プロセスのファイルへの入出力開始地点(ポインタ)を指定するコマンドです。
ここでうまくポインタの指定ができていないと、出力結果に変に空白ができてしまったり、上書きが発生してしまったりします。
| 引数 |
| fh |
ファイルハンドルです。MPI_File_openで設定したファイルハンドルを指定します。 |
| disp |
ポインタのオフセット距離をバイト数で指定します。たとえばここで4を引数として渡した場合、5バイト目にポインタがセットされます。CHARACTER型は1文字1バイトのデータ型なので、この場合はファイルの先頭から4文字分のスペースが空いていることになります。またINTEGER型で考えると、通常は1つ4バイトのデータ型なのでINTEGER1つ分のスペースが空いていることになります。 |
| etype |
ファイルの基本単位を設定します。書き込む際のデータ型もしくはmpi_byteを指定します。
|
| ftype |
ファイルのひとまとまりの単位を設定します。各プロセスが複数回にわたって規則的に入出力を行う際などに利用するもので、決まった型だけでなくユーザーが独自に作ったものを設定することも可能です。各プロセスが入出力を1回しか行わない場合はetypeと同じものを設定しておきます。 |
| datarep |
データの表現方法を指定します。基本的にはバイナリ表現を表す「native」で問題ありません。
※必ず小文字で指定してください。 |
| info |
入出力先のファイル情報を設定できますが、基本的には何も渡さない「mpi_info_null」で問題ありません。 |
| ierr |
正常終了時に0が格納されます。エラー時はそれ以外の値が格納されます |
mpi_file_write
mpi_file_write(fh, buf, count, datatype, status, ierr)
実際にファイルに出力するためのコマンドです。
MPI_File_openでオープンしたファイルにMPI_File_set_viewで指定されたポインタから書き込み始めます。
| 引数 |
| fh |
ファイルハンドルです。MPI_File_openで設定したファイルハンドルを指定します。 |
| buf |
実際に書き込む内容を設定します。 |
| count |
書き込むデータの数(文字数ではない)を設定します。詳しくはdatatypeの欄で説明します。
|
| datatype |
書き込むデータの型です。ここで設定したデータ型を、countで設定した数だけ出力します。
たとえばcharacter型で「hello」と書き込む場合はcountに5を、datatypeにmpi_characterを設定します。
またinteger型で「100」と書き込む場合はcountに1を、datatypeにmpi_integerを設定します。
これはcharacterが1つで1文字を表すデータ型であるのに対し、integerは1つで-2147483648~2147483647の範囲の整数を表すデータ型だからです。 |
| status |
入出力先のファイルの通信に関する設定を行えますが、基本的には何も渡さない「mpi_status_ignore」で問題ありません。 |
| ierr |
正常終了時に0が格納されます。エラー時はそれ以外の値が格納されます |
mpi_file_close
MPI_File_close(fh, ierr)
MPI-IOでの入出力先のファイルをクローズするためのコマンドです。
MPI-IOを行う場合は一連の処理の最後にcallする必要があります。
| fh |
ファイルハンドルです。MPI_File_openで設定したファイルハンドルを指定します。 |
| ierr |
正常終了時に0が格納されます。エラー時はそれ以外の値が格納されます |
ファイルからの入力(読み込み)
上記で作成したoutput.datからデータを読み込み、printで画面に表示するプログラムです。
|
|
program sample include 'mpif.h' !! MPI用のインクルードファイル(必ず指定) integer ierr,myrank,out integer (kind=mpi_offset_kind) idisp call MPI_INIT(ierr) !! MPI並列 開始 call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr) idisp=0+4*myrank call mpi_file_open(mpi_comm_world,'output.dat',mpi_mode_rdwr+mpi_mode_create,mpi_info_null,ifh,ierr) call mpi_file_set_view(ifh,idisp,mpi_integer,mpi_integer,'native',mpi_info_null,ierr) call mpi_file_read(ifh,out,1,mpi_integer,mpi_status_ignore,ierr) call mpi_file_close(ifh,ierr) print '(I2)', out call MPI_FINALIZE(ierr) !! MPI並列 ここまで stop end |
プログラムのハイライト部分(8行目-11行目)が、MPI-IOプログラムになりますが、出力用のプログラムからmpi_file_writeがmpi_file_readに変わったのみでほぼ変化がありません。以下で新たに使用しているmpi_file_readについて解説します。
mpi_file_read
mpi_file_read(fh, buf, count, datatype, status, ierr)
ファイルから読み込むためのコマンドです。
MPI_File_openでオープンしたファイルのMPI_File_set_viewで指定されたポインタからデータを読み込みます。
| 引数 |
| fh |
ファイルハンドルです。MPI_File_openで設定したファイルハンドルを指定します。 |
| buf |
読み込んだデータが格納されます。 |
| count |
読み込むデータの数を設定します。writeのときと同様に文字数ではないという点に注意してください。
|
| datatype |
読み込むデータの型です。ここで設定した型で、countで設定した数だけ読み込みます。 |
| status |
入出力先のファイルの通信に関する設定を行えますが、基本的には何も渡さない「mpi_status_ignore」で問題ありません。 |
| ierr |
正常終了時に0が格納されます。エラー時はそれ以外の値が格納されます |
通常のコマンドを用いた読み込み
MPI-IOを用いて出力されたファイルは通常のreadコマンドでも読み込むことができます。mpi_file_readコマンドは本来、各プロセスにファイルの別々の箇所を読み込ませ、それぞれに並列作業を行わせるためのコマンドですので、MPI-IOによる出力結果をただ読み込むだけならば通常のreadコマンドを用いてデータの読み込みを行います。
上記同様output.datからデータを読み込み、printで画面に出力するプログラムです。
|
|
program sample integer iwrk(20) open(10,file='output.dat',access='direct',recl=4,FORM='BINARY') read(10,rec=1) iwrk close(10) print '(I2)', iwrk end |
ご覧のとおりMPI化を行っていないシリアル実行のプログラムですので、コンパイルやスクリプトでのジョブ投入の記述に誤ってMPI用のコマンドを使わないように注意してください。
C言語の場合
上記と同じプログラムをC言語で記述したものも参考までに掲載します。関数はfortran版とほぼ同じですので、説明は省略します。
ファイルへの出力(書き込み)
|
|
#include <stdio.h> #include <mpi.h> main(int argc, char * argv[]) { int my_rank; MPI_File fh; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); int idisp = 4*my_rank; MPI_File_open(MPI_COMM_WORLD, "output.dat", MPI_MODE_RDWR | MPI_MODE_CREATE, MPI_INFO_NULL, &fh); MPI_File_set_view(fh, idisp, MPI_INT, MPI_INT, "native", MPI_INFO_NULL); MPI_File_write(fh, &my_rank, 1, MPI_INT, MPI_STATUS_IGNORE); MPI_File_close(&fh); MPI_Finalize(); } |
ファイルからの入力(読み込み)
|
|
#include <stdio.h> #include <mpi.h> main(int argc, char * argv[]) { int my_rank, i, out; MPI_File fh; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); int idisp = 4*my_rank; MPI_File_open(MPI_COMM_WORLD, "output.dat", MPI_MODE_RDWR | MPI_MODE_CREATE, MPI_INFO_NULL, &fh); MPI_File_set_view(fh, idisp, MPI_INT, MPI_INT, "native", MPI_INFO_NULL); MPI_File_read(fh, &out, 1, MPI_INT, MPI_STATUS_IGNORE); MPI_File_close(&fh); printf("%d\n", out); MPI_Finalize(); } |
通常の関数を用いた読み込み
|
|
#include <stdio.h> int main(void) { FILE *fp; char *name = "output.dat"; int c[20]; int i; fp = fopen(name, "rb"); fread(&c, sizeof(int), 20, fp); fclose(fp); for(i=0; i<20; i++) printf("%d\n", c[i]); return 0; } |
2017.01.20
SQUID ベクトルノードで実行するNEC MPIにおいて標準出力をリダイレクトする場合は、「/opt/nec/ve/bin/mpisep.sh」スクリプトをご利用ください。
MPIを実行する際、ジョブスクリプトに
|
|
#PBS -v MPISEPSELECT=3 mpirun -np 160 /opt/nec/ve/bin/mpisep.sh ./a.out |
と指定していただくと、標準出力はstdout.0:(MPIプロセスID)、標準エラー出力はstderr.0:(MPIプロセスID)へリアルタイムで出力されます。
これらの詳しい解説は、下記「NEC MPIユーザズガイド」の3.3 MPI プロセスの標準出力 および 標準エラー出力 に記載されております。
NEC MPIユーザズガイド
上記のスクリプトをそのまま使用した場合、stdout/stderrというファイル名になってしまいますが、ご自身でmpisep.shを修正いただくと、任意の名前に変更することも可能です。
2016.08.25
ノード時間を残高以上に使用した場合(ノード時間を使い過ぎてしまった場合)に、そのような表記になります。
※当センターではノード時間を1日に1度取得しますので、ノード時間の残高以上の計算も実行できてしまいます。
本来ですと、ノード時間を使い切った時点で、
(1)ジョブの新規投入
(2)投入されている全てののジョブの実行
の両方を止めるべきなのですが、当センターのシステムの都合により、(2)を止める機能を搭載できていないため、このようなこととなります。
たとえば、8月1日時点で、usage_viewは下記のような表示だったとします。残りノード時間(remaining)は200ノード時間です。
[ SX-ACE ]
shared use : 300 / 500 node-hour (remaining : 200 node-hour)
仮に、8月1日にSX-ACEで20ノードを使った、15時間のジョブを実行したとしますと、計300ノード時間を消費することになります。
8月2日のusage_viewは下記のようになり、残りノード時間(remaining)に負の値が表示されます。
[ SX-ACE ]
shared use : 600 / 500 node-hour (remaining : -100 node-hour)
使いすぎてしまった分については、改めて料金を請求することはございませんので、ご安心くださいませ。
ただし、もし年度中に「資源追加」された場合は、使い過ぎてしまったノード時間分を追加分から差し引いて処理することになりますので、ご了承くださいませ。
年度を越えた際に、使用されたノード時間の情報は全てリセットされます。
2016.08.24
利用者様の方で、ご自身のディスク領域に対して、特定のライブラリやアプリケーションをインストールされる場合、許可は不要です。(管理者権限を要しない場合は、許可不要です。)
センター側でのインストールを希望する場合は、下記のお問い合わせフォームよりご連絡くださいませ。(管理者権限を要する場合は、ご連絡ください。)
お問い合わせフォーム
ライブラリやアプリケーションの内容によっては、お断りする場合や、利用者様自身でのインストールをお願いする場合がございます。あらかじめご了承くださいませ。
2016.08.24
はい。各計算機資源に対して、Pythonの利用環境を提供しております。
2016.08.24
ワークフロー実行機能あるいはリクエスト連携機能を使用することで可能です。
ワークフロー実行についての詳細は下記マニュアルの7.ワークフローをご参照くださいませ。
リクエスト連携機能については下記マニュアルの1.2.22. リクエスト連携機能をご参照くださいませ。
NQS利用の手引き
ワークフロー実行とリクエスト連携機能の違いについて
ワークフロー実行とリクエスト連携機能とではアサインされるタイミングが異なります。ワークフローの場合、投入後すぐに全リクエストがアサイン対象になりますが、リクエスト連携機能の場合、前のリクエストの実行が完了した時点でアサインされます。そのため、混んでいる場合にはワークフローの方が早く実行される可能性があります。
2016.08.24
ほぼ全ての環境変数は、#PBS -v によってMPIスレーブノードに対しても指定することができますが、いくつかの環境変数はスケジューラNQSIIの標準機能(#PBS -v)で指定することが出来ません。PATHもその一つになります。指定できない環境変数については下記マニュアルの1.16 qsub(1)をご参照ください。
NQSII 利用の手引き(OCTOPUS)
NQSV 利用の手引き(SQUID)
MPI実行時オプションをご利用いただくことで、これらの環境変数をスレーブノードに対して設定することが可能です。
2015.11.10
F_UFMTENDIAN環境変数を指定することで可能です。
ただし、当センターで採用しておりますスケジューラ(NQSII)の仕様で、「setenv」で環境変数を指定すると、マスターノードにのみ有効に働き、スレーブノードには反映されません。(マルチノードジョブの場合です。シングルノードジョブの場合ですとsetenvでも問題なく動作します。)
ジョブスクリプトの中で、以下のように指定していただくと、すべてのノードに反映されます。
--------------
#PBS -v F_UFMTENDIAN=[装置番号]
--------------
【参考情報】
ジョブスクリプト 環境変数の指定
NQSIIマニュアル(p.342 - p.343) ※利用者番号で認証が必要
2015.03.04
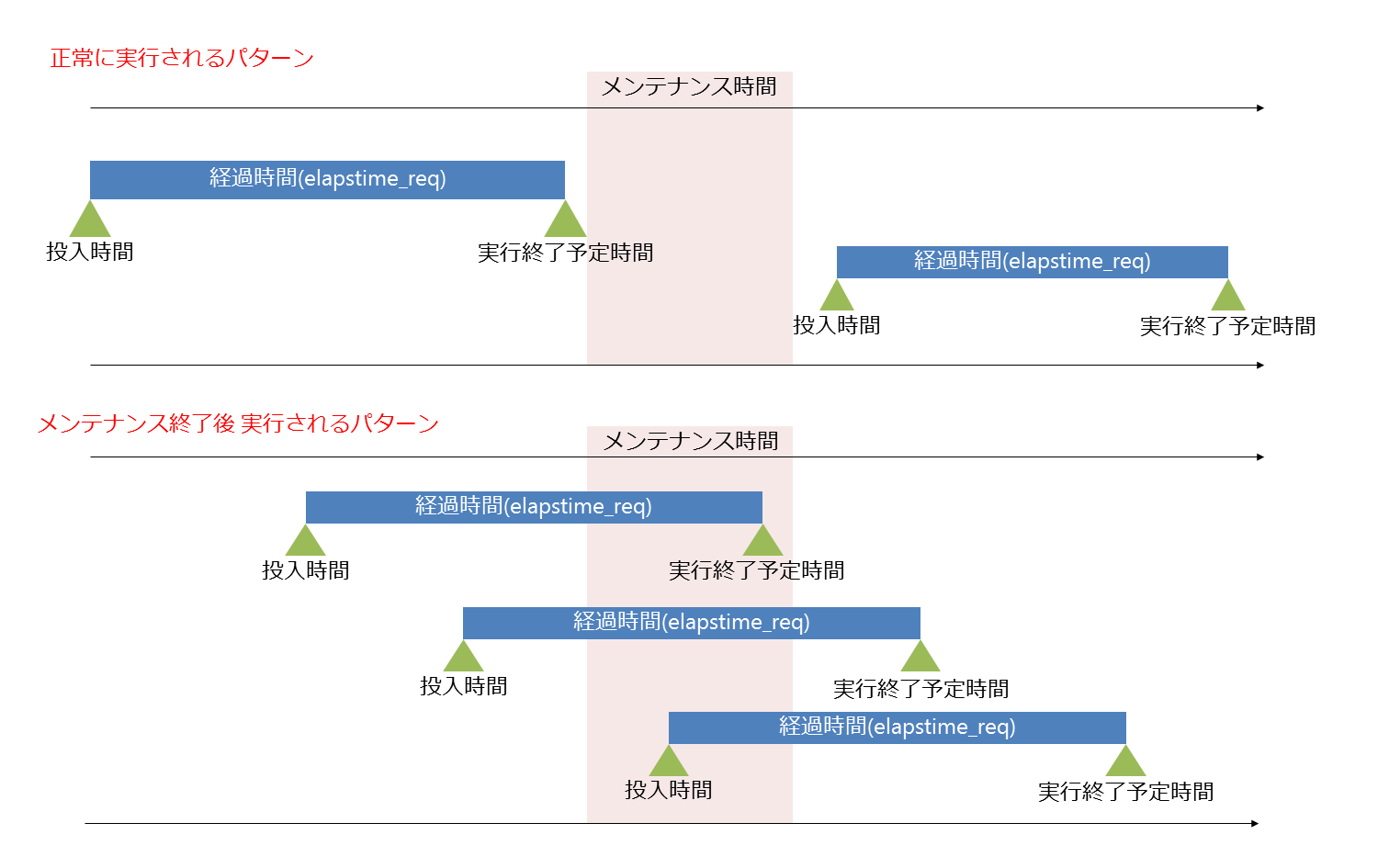
ジョブの投入時間と経過時間の指定により、実行されるタイミングがやや異なりますが、基本的には正しく実行されます。
※共有利用の場合は、他の利用者の投入状況によって実行されない場合がございます。
詳細は下記をご覧ください。
メンテナンス前にジョブを投入した場合
投入したジョブの実行終了予定時刻が、メンテナンス開始時刻を超えていた場合、メンテナンス終了後まで実行されません。
実行終了予定時刻は、「投入時間」とジョブスクリプトに記載した「経過時間の指定(elapstime_req)」から算出します。
例えば、ジョブスクリプトに「elapstime_req=5:00:00」と記載したジョブを、13:00に投入した場合、
実行終了予定時刻は18:00となります。
※共有利用の場合は、上記に関わらず、他の利用者の投入状況によって実行されない場合がございます。
※年度末メンテナンスの場合、メンテナンス終了時点で全てのジョブを削除します。
ジョブの実行終了予定時刻がメンテナンス開始時刻を超えていない場合
正常に実行されます。(メンテナンスの終了を待たずに実行可能です)
ジョブの実行終了予定時刻がメンテナンス開始時刻を超えている場合
前述の通り、メンテナンス終了後まで実行されません。
投入されたジョブはQUE状態のまま受け付けられ、メンテナンス終了後に実行されます。
年度末メンテナンスの場合、全てのジョブが削除されますのでご注意ください。
「経過時間の指定(elapstime_req)」を調整し、
実行終了予定時刻がメンテナンス時刻を超えないようにして、再投入することで、実行できる可能性があります。
もしお急ぎの場合は、お試しください。
メンテナンスが計画された時点で、メンテナンス開始時刻を超えるジョブを実行している場合
占有利用等で、長時間のジョブを実行されている方が対象となります。
メンテナンス開始までは正常に実行されます。
メンテナンス中は、計算を実行できませんので、停止をお願いすることがございますが、ご了承ください。
該当している場合、こちらからご連絡いたします。
メンテナンス中にジョブを投入した場合
メンテナンス終了後まで実行されません
投入されたジョブはQUE状態のまま受け付けられ、メンテナンス終了後に実行されます。
メンテナンス後にジョブを投入した場合
正常に実行されます。
2015.02.10
(質問の補足)
計算機で下記のような処理を行ったとします。
./a.out > output.txt
a.outの実行結果はoutput.txtに書き込まれるのですが、計算中にoutput.txtを確認しても、出力結果が反映されるのが非常に遅いのではないか、という質問です。
(回答)
データ書き込みは、下記のような仕組みで行っています。
それぞれバッファやキャッシュに溜め込む形で、書き出し処理を行っているため、フロントエンドでファイルが確認できるまで時間を要します。
「1. FORTRAN側の動作」による影響は小さいと予想されるため、時間がかかる原因としては主に「2. ファイルシステム側の動作」のデータキャッシュサイズによるものです。
リアルタイムに近い出力を希望される場合、FORTRANプログラム内にて、print実行後に、call flush(6) を実行し、標準出力への内容をフラッシュしていただく必要があります。
これにより、flush実行毎にリダイレクト先ファイルへ反映されます。
※当センターのファイルシステムは、ScateFS(Scalable Technology File System)という独自のファイルシステムを搭載しております。「2.ファイルシステム側の動作」の挙動はScateFSの仕様によるものです。
※sxf03コンパイラは対応していません。
関連するFAQ
SX-ACEの標準出力で、MPIの計算結果をリアルタイムに確認したい
2014.12.11
基本的に、再コンパイルが必要となります。移行手順は以下をご参照ください。
SX-ACEからSX-Aurora TSUBASAへの移行の流れ
2014.07.14
「qwait」コマンドを使用することで、実現可能です。
このコマンドは引数で与えたリクエストID(例:12345.cmc)を待ち合わせするというものです。
指定のリクエストIDのジョブが終了するとメッセージ終了と共にコマンドが終了します。
コマンドの詳細についてはポータルで公開されておりますマニュアル
「NQS利用の手引」のリファレンス編 第1章 ユーザコマンドをご参照頂けますようお願い致します。
NQSII利用の手引き(要認証)
NQSV利用の手引き
※ man qwait でもヘルプを参照できます。
qwait については下記のような使い方が可能です。
監視スクリプトをバックグラウンド実行し、スクリプト内で qwaitを実行します。
exitコード(上記のマニュアルに記載があります)で判定し、その後の動作を分岐させています。
参考にしてください。
-----------
$ qsub job1-1
Request 12345.cmc submitted to queue: Pxx.
$ (./chkjob >& log &)
----- chkjob
#!/bin/sh
while :
do
qwait 12345.cmc #リクエストIDを任意のものに変更して下さい
case $? in
0) qsub job1-2;exit;;
1) qsub job2-1;exit;;
2) qsub job3-1;exit;;
3) echo NQS error | mail xxxx@yyyy.ac.jp;exit;;#メールアドレスを任意のものに変更してください
7) continue;;
*) ;;
esac
done
------------
以上です。
