2024.04.23
特定のサブルーチンに対してVH CALLを使用することで、VHでの計算が可能です。詳細な手順は以下のAurora Forumに掲載しておりますので、ご一読ください。
libvhcall-fortran
動作確認を実施いただくための簡易プログラムを以下に用意しております。
VH CALL動作確認用プログラム
コンパイル方法
module load BaseVEC/2024
sh comp.sh
投入方法(投入前にrun.shを編集しgroupの指定を変更してください)
qsub run.sh
2024.04.18
汎用CPUノード単位の最大メモリ使用量は「qstat -Jf」を定期的に実行することで採取可能です。
qstat -Jf でジョブが使用しているメモリcgroupサイズ(Memory Cgroup Resources)のうち、「Memory Usage」が現在のメモリ使用量、「Max Memory Usage」が最大メモリ使用量を表しています。
2023.06.26
SQUIDでは、acstatコマンドを使って過去に実行したジョブの経過時間を取得可能です。メモリ使用量については取得できませんので、以下のお問い合わせフォームからご連絡くださいませ。
OCTOPUSについては、経過時間・メモリ使用量ともに取得できません。同じく、以下のお問い合わせフォームからご連絡くださいませ。
お問い合わせフォーム
2022.12.09
OpenMPIについては独自にインストールしてご利用することが可能です。
MPIのパスを記載したmoduleファイルを作成してください。
|
|
#%Module 1.0 # # OMP-sample # proc ModulesHelp { } { puts stderr "OMP-sample\n" } prepend-path PATH /sqfs/work/(MPIインストール先)/bin prepend-path LD_LIBRARY_PATH /sqfs/work/(MPIインストール先)//lib/ setenv MPI_ROOT /sqfs/work/(MPIインストール先)/ |
ジョブスクリプトの中で以下のようにmoduleファイル指定してください。
|
|
#PBS -T openmpi #PBS -v NQSV_MPI_MODULE=moduleファイルへの(フルパス) |
2022.10.24
比較的簡単に実施できる方法を2点ご紹介いたします。
ブラウザで共有したファイルを確認・操作いただく場合は、ONION-fileを併用する(1)の手順となります。
S3コマンドで共有したファイルを確認・操作いただく場合は(2)の手順となります。(1)と(2)は併用可能です。
(1)ONION-objectとONION-fileを組み合わせて共有する場合
ONION-objectのバケットをONION-fileで連携し、アクセス用のURLを発行して共有します。
- ONION-objectにて共有するバケットを作成してください。手順はこちらをご参照ください。
- ONION-fileにログインし、ONION-objectで作成したバケットを連携してください。手順はこちらをご参照ください。※ONION-fileへアクセスするアカウントは、スパコンの利用者番号です。連携時にアクセスキーが必要になります。こちらの手順で作成してください。
- 連携したバケットにてファイル共有機能を使用し、共有用のURLを発行してください。手順はこちらをご参照ください。URLからダウンロードやアップロードが可能です。
(2)ONION-objectだけで共有する場合
ONION-objectのバケットに対して任意のグループ/アカウントにアクセス権を付与します。
- ONION-objectにて、共有相手のアカウントを発行してください。手順はこちらをご参照ください。その後、共有するバケットを作成してください。手順はこちらをご参照ください。
- バケットのアクセス権を設定します。バケット名右側のプロパティを選択→個別アクセス権→「+新規追加」を選択し、グループ・ユーザー欄に、共有相手のユーザアカウントを指定します。書式はGroup|Userといったように、|で区切ります。(例えば、グループがGROUP-123でアカウント名がUSER-456でしたらGROUP-123|USER-456と記載してください)
必要に応じて、読み出し可能/書き出し可能のチェックボックスにチェックを入れてください。アクセス権を付与したユーザからバケットが見れるようになります。
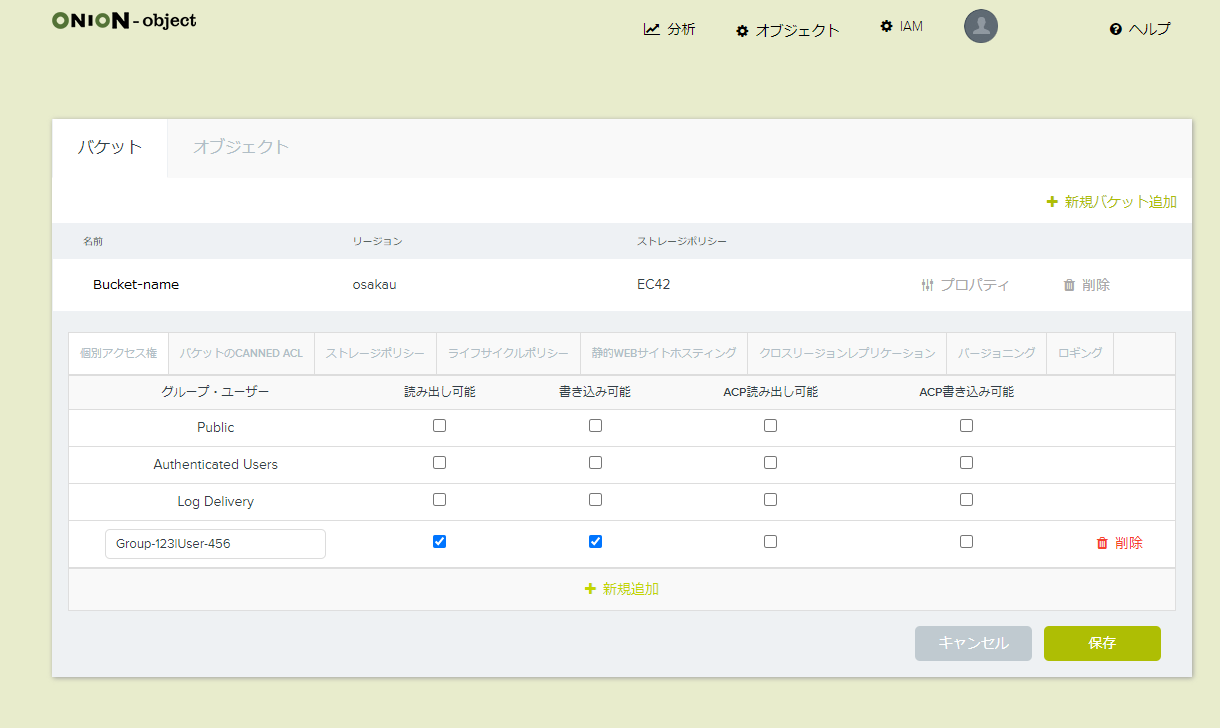
ただし、共有相手側のONION-object管理画面には、共有したバケットは表示されず、自分自身のバケットしか見れません。基本的に、共有相手側はS3コマンドで確認いただくことになります。S3コマンドの操作はこちらをご参照ください。
2022.10.13
本エラーは、書式なしの入出力文の並びに配列が指定されており、その配列サイズが大きい場合に発生するエラーです。
以下のコンパイラオプション、実行時環境変数を指定して実行いただくことで特定可能です。
★のように、エラーの出たファイルと行数が表示されます。
例)
$ nfort main.f90 -g -traceback=verbose
$ export VE_TRACEBACK=VERBOSE
$ ./a.out
Runtime Error: Cannot allocate memory for environment variable VE_FORT_UFMTENDIAN.
Program terminated by fatal error
[ 0] 0x600c00a58910 ? ?:?
[ 1] 0x600c00a51b38 ? ?:?
[ 2] 0x600c00cd4c78 ? ?:?
[ 3] 0x60000001f850 MAIN main.f90:28 ★
[ 4] 0x60000001fc80 ? ?:?
[ 5] 0x600c02a407a8 ? ?:?
[ 6] 0x600000002d00 ? ?:?
2022.10.13
wandbについてはpipコマンドにてインストール可能です。
pip install wandb
wandb login "XXXX"
SQUIDでは原則計算ノードからのインターネットアクセスを許可しておりませんが、wandbに限定して許可しています。
以下のようにジョブスクリプトを記述してください。
#!/bin/bash
#PBS -q SQUID
#PBS --group=[グループ名]
#PBS -l elapstim_req=1:00:00
cd $PBS_O_WORKDIR
export http_proxy="http://ibgw1f-ib0:3128"
export https_proxy="http://ibgw1f-ib0:3128"
python test.py
requests-2.24を使用してください。2.26等のバージョンについては、SQUIDで正常に動作しません。
2022.01.18
SQUIDでは環境変数 $NQSII_MPIOPTS / $NQSV_MPIOPTによって、#PBS -l cpunum_jobで指定した値を元に、machinefileを自動生成しMPIに設定しています。ppn, rr, prehostといったオプションはmachinefileと同時に指定することが出来ないため、仮に128 MPIプロセス / 1ノードあたり64プロセス割り当てることを想定し、以下のように指定したとしても、ppn オプションは無効となります。
mpirun ${NQSV_MPIOPTS} -np 128 -ppn 64 ./a.out
基本的には以下のように指定いただくことで、128 MPIプロセスを生成し、1ノードあたり64プロセス割り当てることが可能です。
#PBS -l cpunum_job=64
(中略)
mpirun ${NQSV_MPIOPTS} -np 128 ./a.out
環境変数 $NQSV_MPIOPTS は、以下のオプションとファイルが指定されています。
-machinefile /var/opt/nec/nqsv/jsv/jobfile/[リクエストID等の数値]/mpinodes
mpinodesファイルはマシンファイルとなっており、上記の場合は以下のようなホスト名、コア数が指定されています。
host001:64
host002:64
ただし、より細かくプロセス配置を指定したい場合(例えばピニングを設定し特定のコアにプロセスを使用せずに計算する場合など)上記のオプションでは対応出来ないケースがあります。ppn, rr, prehostオプションを使用する場合は、環境変数 $NQSII_MPIOPTS / $NQSV_MPIOPT を指定する代わりにhostfileオプションと環境変数 $PBS_NODEFILE を指定してください。128 MPIプロセスを生成し、1ノードあたり64プロセス割り当てる場合は以下のように指定します。
mpirun -hostfile ${PBS_NODEFILE} -np 128 -ppn 64 ./a.out
※PBS_NODEFILEを使う場合、#PBS -l cpunum_jobで指定した値がMPIに設定されません。ご自身でプロセス数の確認をお願いします。また、OCTOPUSではご利用いただけません。
2021.11.26
以下のコマンドで取得可能です。ジョブスクリプトの最後で実行してください。
$ nvidia-smi --query-accounted-apps=timestamp,gpu_name,gpu_bus_id,gpu_serial,gpu_uuid,vgpu_instance,pid,time,gpu_util,mem_util,max_memory_usage --format=csv
出力例は以下のとおりです。最後に記載されている523MiBがGPUで使用した最大メモリサイズです。
2021/11/24 19:26:26.333, A100-SXM4-40GB, 00000000:27:00.0, 1564720026417, GPU-a3b25bed-7bb1-cbd8-89e3-3f14b6118874, N/A, 761279, 117202 ms, 2 %, 0 %, 523 MiB
ジョブクラス「SQUID-S」を使用している場合は、同じノード内で別の方のジョブが実行されている場合があるため、正しい値が取得されない可能性があります。予めご了承ください。
2021.11.08
2段階認証コードのリセットには管理者の操作が必要となりますので、お問い合わせフォームからお知らせください。その際、氏名、利用者番号、メールアドレスは登録時のものを記入してください。2段階認証のリセット時にパスワードもあわせて初期化いたしますので、予めご了承ください。
お問い合わせフォーム
アカウントの所有者が卒業してしまった等、本人からの連絡が難しい場合に限り、当該アカウントに登録されている指導教員またはグループの申請代表者からの2段階認証リセットの依頼にも対応します。
2021.11.08
ご自身でインストールすることで、利用可能です。手順は以下のとおりです。
python venvを使用する
インストール手順
|
|
# Python+GPUのEnvironmental modulesを設定する module load BasePy module --force switch python3/3.6 python3/3.6.GPU module load BaseGPU module load cudnn/8.2.0.53 #Pytorchをインストールする仮想環境 test-envを作成し、Activateする python3 -m venv /sqfs/work/【グループ名】/【ユーザ名】/test-env/ source /sqfs/work/【グループ名】/【ユーザ名】/test-env/bin/activate # SQUIDのGPUノード(A100)に対応するCUDA11.1 + Pytorchをインストール pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html |
利用手順(ジョブスクリプト例)
|
|
#!/bin/bash #PBS -q SQUID #PBS --group=(グループ名) #PBS -l elapstim_req=1:00:00,gpunum_job=8 cd $PBS_O_WORKDIR module load BasePy module --force switch python3/3.6 python3/3.6.GPU module load BaseGPU module load cudnn/8.2.0.53 source /sqfs/work/【グループ名】/【ユーザ名】/test-env/bin/activate python test.py |
mini-forgeを使用する
まず以下のページを参考にminiforgeをインストールしてください。
miniforgeのインストール・使い方(SQUID)
次に、以下を参考にPytorchをインストールしてください
|
|
# miniforge仮想環境の作成準備 conda config --add envs_dirs /sqfs/work/(グループ名)/(利用者番号)/conda_env conda config --add pkgs_dirs /sqfs/work/(グループ名)/(利用者番号)/conda_pkg #Pytorchをインストールする仮想環境 test-envを作成し、Activateする conda create --name test-env python=3.8 conda activate test-env # SQUIDのGPUノード(A100)に対応するCUDA11.1 + Pytorchをインストール conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge |
1ノードでの利用手順(ジョブスクリプト例)
|
|
#!/bin/bash #PBS -q SQUID #PBS --group=(グループ名) #PBS -l elapstim_req=1:00:00,gpunum_job=8 cd $PBS_O_WORKDIR conda activate test-env python test.py |
2ノードでの利用手順(ジョブスクリプト例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/bin/bash #PBS -q SQUID #PBS --group=(グループ名) #PBS -b 2 #PBS -l gpunum_job=8 #PBS -l elapstim_req=01:00:00 cd $PBS_O_WORKDIR source ~/.bashrc conda activate test-env echo "===================" MASTER_NODE=`head -1 ${PBS_NODEFILE}` USE_PORT=12321 HOSTNAME=`hostname -s` echo "-------------------" echo "HOSTNAME =[${HOSTNAME}] MASTER_NODE=[${MASTER_NODE}] USE_PORT=[${USE_PORT}]" echo "===================" python -m torch.distributed.launch --nnodes=2 --nproc-per-node=8 --rdzv-id=100 --rdzv-backend=c10d --rdzv-endpoint=${MASTER_NODE}:${USE_PORT} test.py |
2021.10.11
ワークフローにてA⇒Bの順序で制御しているときに、AがRERUNとなった場合、Aを再実行、Bは再スケジューリングされ、ワークフローの順番を保ったまま実行されます。
2021.05.18
ベクトルノード群の場合、実行時に以下の環境変数を指定いただくことでNaNを含む無効演算例外を検知することが可能です。
(NaNを演算に使用されるとエラーとなります。)
export VE_FPE_ENABLE=INV
詳細は、以下のマニュアル 6ページ「1.9 演算例外」の項目をご参照ください。
SX-Aurora TSUBASA Fortran コンパイラ ユーザーズガイド
また、エラーを検知した該当箇所を確認する場合は以下も合わせてご指定ください。
コンパイラオプション:-traceback=verbose -g
実行時環境変数:export VE_TRACEBACK=VERBOSE
詳細は上記マニュアルの24ページに記載しております。
2021.05.14
qstatコマンドを実行すると、SX-Aurora TSUBASA(ベクトルエンジン)が接続されているLinux(ベクトルホスト)のCPU時間や使用メモリが表示されます。SX-Aurora TSUBASA(ベクトルエンジン)の情報を確認する場合は以下のオプションを指定してください。
|
|
$ qstat -J -e #実行結果例 JNO RequestID EJID VEMemory VECPU JSVNO VectorIsland UserName Exit ---- --------------- ----- -------- -------- ----- --------------- -------- ---- 0 1000.sqd 896040 10.38G 147578.00 4100 vec0100 user01 - 0 1001.sqd 129054 20.45G 15251.00 4101 vec0101 user01 - 0 1002.sqd 2138470 21.35G 5668.00 4102 vec0102 user01 - 1 1002.sqd 2138455 21.35G 6503.00 4102 vec0102 user01 - 0 1003.sqd 1813977 21.54G 33667.00 4103 vec0103 user01 - 1 1003.sqd 1814130 21.54G 32972.00 4103 vec0103 user01 - |
1行に出力される情報は、投入するジョブクラスによって異なります。
DBGやSQUID-Sに投入した場合:ベクトルエンジン1台分の使用メモリ量、CPU時間を表示します
SQUIDやSQUID-Hに投入した場合:ベクトルエンジン8台分の使用メモリ量、CPU時間を表示します
2021.05.14
SX-ACEでは標準で出力されていましたが、SX-Aurora TSUBASAではコンパイル時および実行時にオプションを設定する必要があります。
コンパイラオプションでproginfオプションを指定してください。
nfort -proginf test.f90
また、ジョブスクリプトで以下を指定してください。
export VE_PROGINF=YES
または
export VE_PROGINF=DETAIL
2020.03.10
HPCI以外のグループからHPCI共用ストレージをマウントしたい / 阪大を利用しないHPCI課題で採択されたHPCI共用ストレージをマウントしたい場合、以下のような手順となります。事前に、マウントポイントを用意する必要がありますので、こちらからお問い合わせください。
1. HPCI 証明書発行システムで代理証明書を発行し、リポジトリに格納します。
2. フロントエンドサーバにログイン後、次のコマンドを実行し、代理証明書をダウンロードしてください。
myproxy-logon -s portal.hpci.nii.ac.jp -l hpciXXXX(HPCI-ID) -t168
3. 次のコマンドを実行し、HPCI共用ストレージを「/gfarm/(project ID)/(user ID)」(マウントポイント)にマウントします。
mount.hpci
4. 利用を終了次第、HPCI共用ストレージをアンマウントします。
umount.hpci
HPCI共用ストレージについては、こちらのHPCI共用ストレージ利用マニュアルをご参照ください。
2019.12.05
ファイル名に連続した数値が含まれている場合、パラメトリックジョブという投入方法で、一度に大量のジョブを投入できます。
パラメトリックジョブでは、ジョブスクリプト内の"$PBS_SUBREQNO"環境変数に、-tで指定した数値(下記の例では1から5までの数値)が格納されます。
qsubすると同時に5本のジョブが投入され、a.outに対してそれぞれ異なる入力ファイル(下記の例ではinput1からinput5)が設定されます。
ジョブスクリプト例
|
|
#PBS -q OCTOPUS #PBS -l elapstim_req=0:30:00,cpunum_job=24 cd $PBS_O_WORKDIR ./a.out input$PBS_SUBREQNO |
投入例
qstatの表示例:パラメトリックジョブの場合、1回のqsubにつき1件分の表示となります
|
|
RequestID ReqName UserName Queue Pri STT S Memory CPU Elapse R H M Jobs --------------- -------- -------- -------- ---- --- - -------- -------- -------- - - - ---- 123456[].oct nqs username OC1C 0 QUE - - - - Y Y Y 1 |
sstatの表示例:-tで指定した数値分だけ表示されます
|
|
RequestID ReqName UserName Queue Pri STT PlannedStartTime --------------- -------- -------- -------- ----------------- --- ------------------- 123456[1].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[2].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[3].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[4].oct nqs username OC1C 0.5002/ 0.5002 QUE - 123456[5].oct nqs username OC1C 0.5002/ 0.5002 QUE - |
2019.11.25
OCTOPUSには以下のGnuplotがインストールされています。
・4.6 (デフォルト)
・5.2.4 (/octfs/apl/Gnuplot/5.2.4)
Octaveから呼び出されるGnuplotのバージョンは、以下の2通りの方法で指定が可能です。
・呼び出したいバージョンのパスを設定する
下記のジョブスクリプト例の4行目のように、Octaveの実行の前にGnuplotのバージョンのパスを設定することで、呼び出すバージョンを指定することができます。(Gnuplot5.2.4を呼び出す場合の例です)
パスを設定しない場合、デフォルトのバージョンが呼び出されます。
|
|
#!/bin/bash #PBS -q OCTOPUS #PBS -l elapstim_req=1:00:00 export PATH=/octfs/apl/Gnuplot/5.2.4/bin:$PATH cd $PBS_O_WORKDIR /octfs/apl/Octave/5.1.0/bin/octave-5.1.0 file.m |
・Octaveの設定ファイル「.octaverc」を作成する
ホームディレクトリにOctaveの設定ファイル「.octaverc」を作成し、下記の一文を記述してください。
gnuplot_binary="[Gnuplotの実行ファイルのパス]"
上記のように記述することで、Octaveから呼び出されるデフォルトのGnuplotの実行ファイルを設定できます。
例えば、5.2.4を呼び出す場合は「gnuplot_binary="/octfs/apl/Gnuplot/5.2.4/bin"」と記述してください。
2019.04.11
MPIプログラム実行時に${NQSII_MPIOPTS}を指定していなかった場合、以下のようなエラーが出力されます。
[mpiexec@oct-***] HYDT_bscd_pbs_query_node_list (../../tools/bootstrap/external/pbs_query_node_list.c:23): No PBS nodefile found
[mpiexec@oct-***] HYDT_bsci_query_node_list (../../tools/bootstrap/src/bsci_query_node_list.c:19): RMK returned error while querying node list
[mpiexec@oct-***] main (../../ui/mpich/mpiexec.c:621): unable to query the RMK for a node list
以下のページに、MPIプログラムを実行する際のジョブスクリプトの例を掲載しておりますので、まずご参照ください。
OCTOPUSでのintel MPI実行方法
エラーメッセージ自体は、MPIプログラムの"nodefile"(実行する計算ノードを指定する設定ファイル)が存在しないことを通知しています。OCTOPUSでは、${NQSII_MPIOPTS}を指定いただくことで、自動的に設定されます。
2019.04.11
資源に空きがある限り、複数のジョブを同時に実行可能です。
qsub A.nqs
qsub B.nqs
といったように、1件1件個別にqsubしていくことで、A.nqsとB.nqsが同時に実行可能な状態となります。
2019.01.10
MPI並列実行を行うプログラムで各プロセスが同名ファイルにデータを出力するよう記述していると、バイナリが書き込まれてしまう場合があります。
大規模計算機システムのような共有ファイルシステムにおいて各プロセスが同名のファイルにデータを出力することは、各プロセスが同一のファイルにデータを出力することと同じであるため、プロセス間で競合が発生した際にデータが破損してしまい、バイナリデータが書き込まれてしまうことがあります。各プロセスごとに別名のファイルに出力するか、MPI-IOというMPI用の入出力インターフェースを利用することで、プロセス間の競合を防ぐことが可能です。
MPI-IOについては下記をご覧ください。
MPIの実行結果を1つのファイルに出力したい
2018.12.20
利用者単位、計算機単位でジョブの投入数上限を設定しており、いずれかの上限を超過していることによるエラーとなります。
基本的には、誤った利用方法による事故を防ぐ目的で設定しているものであり、利用を阻害するために設けているものではありませんので、本エラーを確認された場合は、以下までお知らせください。
お問い合わせフォーム
2018.11.16
試用制度のアカウントを一般利用へ引き継ぐことが可能です。アカウント情報、ストレージのデータなどをそのままご利用いただけます。
引継ぎを行う場合、下記の利用者管理システムから「利用資源追加申請」を行ってください。
利用者管理システム
「利用資源追加申請」の手順については下記のページに掲載しています。
利用資源追加申請
2018.08.02
XQuartsの仕様変更により、Xwindowを使用する場合に正しく起動しないことがあります。
対策
1. MacOS の xterm 上で以下のコマンドを実行してください。
XQuarts 2.7.10 以降で、iglx が標準で使えなくなったため、以下のコマンドを実行しないとエラーが出力されます。
$ defaults write org.macosforge.xquartz.X11 enable_iglx -bool true
2. SSH の X 転送を早くするチューニングを実施してください。
JavaFX使用する一部のアプリケーションでは、上記設定にて若干挙動が軽くなる可能性があります。
<.ssh/config 設定例>
Host *
Compression yes
ForwardX11 yes
Ciphers blowfish-cbc,arcfour
2017.11.27
接続を行っている端末のターミナルソフトがフロントエンドサーバ接続時に環境変数を引き継ぐように設定している場合、このメッセージが表示されます。以下の2通りの方法をお試しください。
使用しているターミナルソフトの設定を変更する
自身の使用しているターミナル上の/etc/ssh_configファイルの"SendEnv"の記述を下記のようにコメントアウトしてください。
※フロントエンドに接続していない状態で行ってください。
フロントエンドサーバ接続時に自動で環境変数が設定されるようにする(ターミナルの設定を変更したくない場合)
profileファイルに下記のように記述してください。
bashの場合.bash_profileに記述します。
2017.10.30
企業を含め、学外の方との共同研究でも利用可能です。
2017.06.06
計算に使用するノードは、スケジューラ側が自動で最適なノードを割り当てるようになっており、利用者様の方では指定することはできません。
ご理解くださいませ。
2017.06.06
(質問の補足)
OCTOPUS(24コア)4ノードでIntelMPIを使って並列計算を実行する際に、
node 1: rank 0, 1, 2, ... , 24
node 2: rank 25, 26, 27, ... ,48
node 3: rank 49, 50, 51, ... ,72
node 4: rank 73, 74, 75, ... , 96
とするのではなく、
node 1: rank 0, 4, 8, ..., 93
node 2: rank 1, 5, 9, ..., 94
node 3: rank 2, 6, 10, ..., 95
node 4: rank 3, 7, 11, ..., 96
としたいが、どのようにすればよいのか?
(回答)
OCTOPUS(24コア)4ノードで並列計算を実行する場合、ジョブスクリプトで
#PBS -b 4
mpirun {NQSII_MPI_p} -ppn 1 -n 80 ./a.out
と指定してください。
IntelMPIはmpiexecの-ppnオプションに指定した値の数だけ、連続したプロセスをノード毎に割り当てます。
したがって、-ppn 1と指定していただくことで、1ノードに1プロセスずつ割り当てるようになります。
「man mpiexec」コマンドで表示される-ppnオプションの解説(IntelMPI)
-perhost <# of processes>, -ppn <# of processes, -grr <# of processes>
Use this option to place the specified number of consecutive MPI processes on every host in the group using round robin scheduling.
2017.05.29
ラインの太さの調整には以下の2つの方法があります。
ライン自体の大きさを変更する
ライン自体の大きさはglyphモジュールのScaleパラメータで調整が行なえます。
ラインの太さはObjectメニューで変更します。操作手順は以下のとおりです。
1.エディター→Objectを開く
2.ObjectメニューでObject[General]を[Properties]に変更
3.PropertiesのTypeを[General]から[Point/Line]に変更
4.Line Thicknessのスライダーで太さを調整
tubeモジュールを使用する
ラインの太さを変更しても、OputputImageで画像サイズを大きくして出力した場合相対的にラインが細く見える場合があります。この場合はTubeモジュールを使用することで画面サイズに応じて太くなる形状を作成できます。
TubeモジュールはMain.Mappers登録されており、ライン表示をしているモジュールの下に接続して利用します。
TubeのメニューのScaleで太さの調節ができます。
以下のリンク先にtubeのサンプルデータを設置しています。
(ダウンロードして拡張子を「.v」に変更することでモジュールとしてそのまま使用することができます。)
tubeサンプル
以上の点で何かご不明な点がありましたら下記のWEBフォームよりご連絡くださいませ。
お問い合わせフォーム
2017.05.29
coordinate_mathなどで座標の計算が必要な場合になる場合がありますが、V言語での計算式の記述は下記の記述例のようにExcelやC言語とほぼ同じ形式で記述することができます。
記述例
X : (#1x*15)+12
Y : (#1y*15)+12
Z : (#1z*15)+16
指定の#1x,#1y,#1zが座標値の変数です。
また+,-,*,/の四則演算や()による計算順序の指定が行なえます。
ご不明な点がありましたら下記のWEBフォームよりご連絡くださいませ。
お問い合わせフォーム
