更新日時:2023年03月06日 / OCTOPUS
本システムは2024年3月29日をもってサービス終了しました。
「OCTOPUS(Osaka university Cybermedia cenTer Over-Petascale Universal Supercomputer)」は、汎用CPUノード群、GPUノード群、Xeon Phiノード群、大容量主記憶搭載ノード群、大容量ストレージから構成され、総理論演算性能1.463 PFLOPSを有するスーパーコンピュータです。
システム構成
| 総演算性能 | 1.463 PFLOPS | |
|---|---|---|
| ノード構成 | 汎用CPUノード 236ノード (471.24 TFLOPS) |
プロセッサ:Intel Xeon Gold 6126 (Skylake / 2.6 GHz 12コア) 2基 主記憶容量:192GB |
| GPUノード 37ノード (858.28 TFLOPS) |
プロセッサ:Intel Xeon Gold 6126 (Skylake / 2.6 GHz 12コア) 2基 GPU:NVIDIA Tesla P100 (NV-Link) 4基 主記憶容量:192GB |
|
| Xeon Phiノード 44ノード (117.14 TFLOPS) |
プロセッサ:Intel Xeon Phi 7210 (Knights Landing / 1.3 GHz 64コア) 1基 主記憶容量:192GB |
|
| 大容量主記憶搭載ノード 2ノード (16.38 TFLOPS) |
プロセッサ:Intel Xeon Platinum 8153 (Skylake / 2.0 GHz 16コア) 8基 主記憶容量:6TB |
|
| ノード間接続 | InfiniBand EDR (100 Gbps) | |
| ストレージ | DDN EXAScaler (Lustre / 3.1 PB) | |
Gallery



![]()
![]()
![]()
技術資料
更新日時:2021年02月28日 / SX-ACE
本システムは2021年2月28日で提供を終了しました。
| 2020年3月31日まで | 2020年4月1日から2021月年2月28日まで | |
|---|---|---|
| クラスタ数 | 3 | 2 |
| ノード数 | 1536 | 1024 |
| コア数 | 6144 | 4096 |
| 演算性能 | 423TFLOPS | 282TFLOPS |
| ベクトル性能 | 393TFLOPS | 262TFLOPS |
| 主記憶容量 | 96TB | 64TB |
| ディスク容量 | 2PB(変更無し) | |
また、2020年11月30日以降のサービスについて、以下のような変更があります。
- 2020年11月30日以降は、システムの利用に関する質問等の技術的なサポートは利用できません。
- 2020年11月30日以降、「利用資源追加申請」や「新規利用申請」の受け付けを停止します。12月1日から2月28日の間に、共有利用のノード時間やストレージ資源を使い切った場合も、資源の追加は出来ませんので、不足するかもしれない場合は、事前に申請をお願いいたします。
- 現在ご利用中の、共有利用 ノード時間、占有ノード、ディスク領域(home, ext)は、すべて2021年2月28日までご利用可能です。
- 占有ノード、ディスク領域については、利用期間の延長に伴う追加料金は発生しません。
システム概要
サイバーメディアセンターが導入するSX-ACEは、総計1,536ノード構成(3クラスタ)となる”クラスタ化”されたベクトル型スーパーコンピュータです。各ノードは、4コアのマルチコア型ベクトルCPU、64GBの主記憶容量を搭載しています。これら512ノードを、IXS (Internode Crossbar Switch)と呼ばれる専用のノード間スイッチでノード間接続し、クラスタを形成します。なお、本センターでは、このノード間接続装置IXSは、512ノードを2段ファットツリー構成 1 レーンで接続しており、ノード間最大転送性能は入出力双方向それぞれ 4 GB/sとなっています。本センターでは、2 PBのディスクをNEC独自開発のNEC Scalable Technology File System (ScaTeFS)と呼ばれる高速・分散並列ファイルシステムで管理し、SX-ACEを含む本センターの大規模計算機システムからアクセス可能な構成としています。
ノード性能
各ノードは、64 GFlopsのベクトル演算性能を有するコアを 4 個保有するマルチコア型ベクトルCPU、64 GBの主記憶容量を搭載しており、ノード単体のベクトル演算性能は256 GFlopsとなります。一方、ノード内におけるCPUと主記憶間の最大転送能力は、256 GB/sを保有しています。すなわち、1 Byte/Flopsの高いCPU性能にバランスした高メモリバンド幅が実現されており、気象・気候、流体シミュレーションに適した演算性能とメモリバンド幅バランスを提供するシステムとなっています。
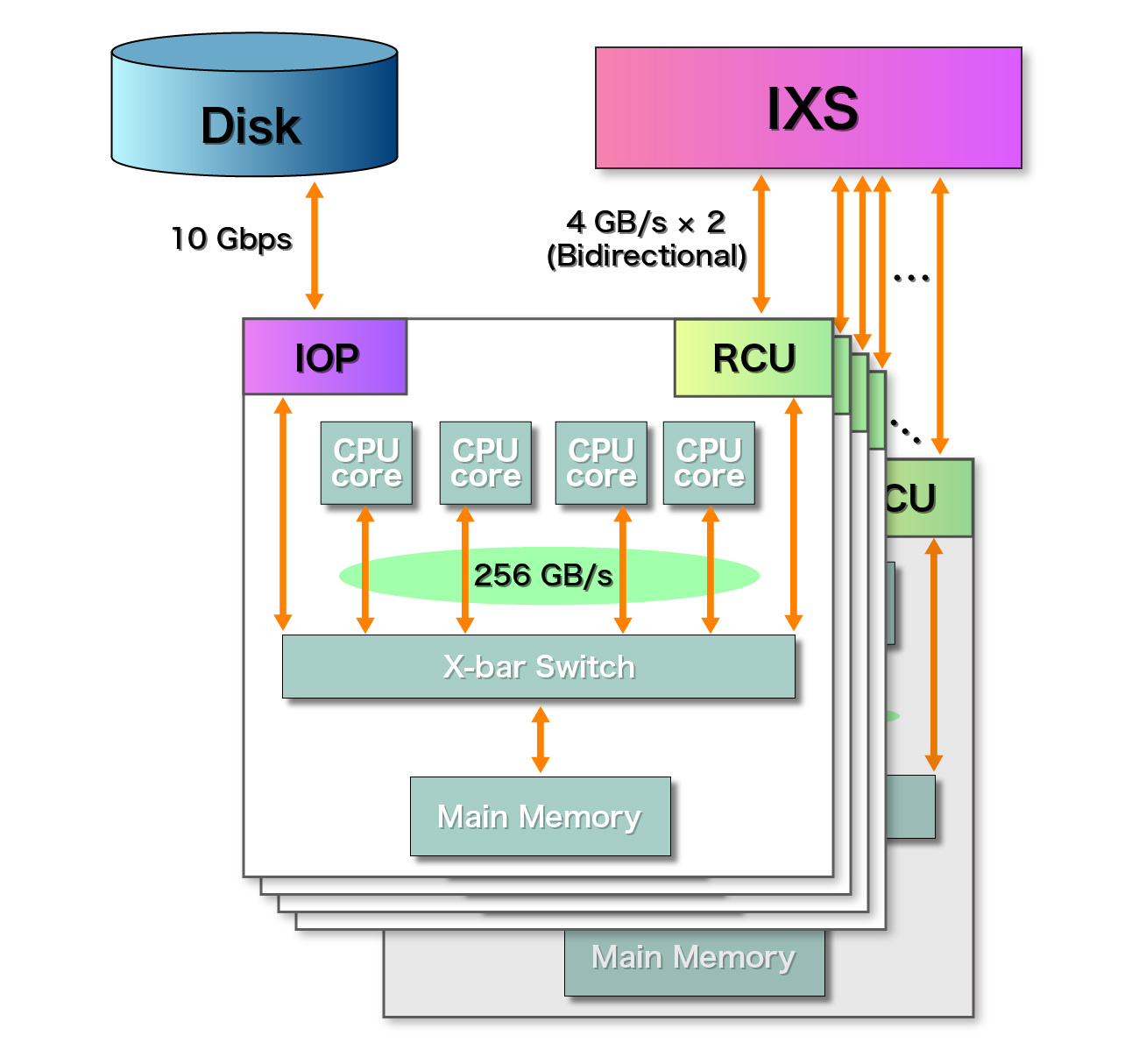
ノード間の通信は、RCUと呼ばれるノード間通信制御ユニットが専用ノード間スイッチIXSと接続されており、8 GB/s (4GB × 2(双方向))での広帯域データ通信が可能です。
システム性能
本センターで導入するSX-ACEは、3 クラスタ(総計1536ノード)から構成されます。そのため、1 クラスタおよび 3 クラスタあたりの理論性能値は、ノード単体性能から簡単な計算で、下記のとおり導かれます。
|
SX-ACE
|
|||
| ノード毎 | 1クラスタ(512ノード) | 総合(3クラスタ) | |
| CPU数 | 1 | 512 | 1536 |
| コア数 | 4 | 2048 | 6144 |
| 演算性能 | 276GFLOPS | 141TFLOPS | 423TFLOPS |
| ベクトル性能 | 256GFLOPS | 131TFLOPS | 393TFLOPS |
| 主記憶容量 | 64GB | 32TB | 96TB |
| ディスク容量 | 2PB | ||
なお、演算性能は、SX-ACE 1ノードが 4コアのマルチコア型ベクトルCPUに加え、スカラ型CPUを搭載していることから、スカラ型CPUの演算性能とベクトル型 CPUの合計理論性能値となっています。
ソフトウェア
本センターのSX-ACEには、オペレーティングシステムとしてSUPER-UX R21.1が採用されています。SUPER-UXはSystem V系のUNIXに基づき、高いユーザエクスペリエンスを提供する一方で、SX-ACEのハードウェア性能を最大限にまで引き出すことのできるオペレーティングシステムです。これまでセンターが保有・提供してきたSX-8R、SX-9でもSUPER-UXがオペレーティングシステムとして採用されてきた経緯があるため、SX-8R、SX-9を利用されてきた利用者の方には親しみやすく、使いやすいオペレーティングシステムです。
また、本センターのSX-ACEでは、SUPER-UX上で動作、チューニングがなされた下記のソフトウェア、ライブラリを提供します。
| SX-ACE | |
|---|---|
| 分類 | 機能 |
| 開発環境ソフトウェア | Fortran95/2003コンパイラ C/C++コンパイラ |
| MPIライブラリ | MPI/SX |
| HPFコンパイラ | HPF/SX V2 |
| デバッガ | dbx/pdbx |
| 性能解析ツール | PROGINF/FILEINF FTRACE prof |
| 数値計算ライブラリ | ASL |
| 統計計算ライブラリ | ASLSTAT |
| 数学ライブラリ集 | MathKeisan (ARPACK, BLACS, BLAS, FFT, LAPACK, PARBLAS, PARFFT, PARPACK, CBLAS, SBLAS, ScaLAPACK) |
| 計算化学用ソフトウェア | Gaussian09 |
| フロントエンド | |
|---|---|
| 分類 | 機能 |
| 開発環境ソフトウェア | Fortran95/2003クロスコンパイラ C/C++クロスコンパイラ Intel Cluster Studio XE |
| HPFコンパイラ | HPF/SX V2クロスコンパイラ |
| デバッガ | NEC Remote Debugger |
| 性能解析ツール | FTRACE NEC Ftrace Viewer |
| 汎用可視化ソフトウェア | AVS/ExpressDeveloper |
なお、SX-ACEへのジョブ管理には、JobManipulatorとNQSIIを中核とした統合スケジューラを採用しています。
スケジューラについてはこちらをご参照ください。
チェックポイント/リスタート機能
SX-ACEは、実行中のプログラムを任意の時点で中断させ、メモリ上のデータをディスクに書きだすことで、状態を保存する機能(チェックポイント)を持っています。保存した状態から再開させること(リスタート)も可能です。
例えば、緊急メンテナンスが必要となった場合に、実行中のジョブを一時中断しておき、メンテナンス終了後に再開する、といったことが可能となります。
SX-ACEでの性能チューニング
本センターがこれまで保有・提供してきたベクトル型スーパーコンピュータSX-8R、SX-9では、多数のベクトル型CPUが大規模な主記憶装置上で演算を行う共有メモリ型のスーパーコンピュータでしたが、SX-ACEでは上記のような小規模化したノードが多数接続された分散並列メモリ型のスーパーコンピュータとなっています。分散並列メモリ型のスーパーコンピュータでは、異なるメモリアドレス空間を有するノード間でデータを交換しながら通信を行う必要があります。そのため、SX-ACEでの性能チューニングには、上述したノード内アーキテクチャ、ノード間アーキテクチャ、およびそれらの通信特性に関して基本的な知識を持っておくことが前提となります。
SX-ACE上で性能チューニングを行う方法には、大別して、ノード内並列(共有メモリ並列処理)、ノード間並列(分散メモリ並列処理)の2種類があります。前者のノード内並列処理は、SX-ACEのノード内に搭載されたベクトル型CPU4コア内で計算負荷を分散する方法です。後者のノード間並列処理は、SX-ACEの複数のノードに計算負荷を分散する方法です。
ノード内並列(共有メモリ並列処理)
この方法の特徴は、ベクトル型CPU4コアが主記憶64GBのメモリ空間を”共有”することにあります。一般的に、並列計算においては、分散メモリ型より共有メモリ型のほうがプログラミング、チューニングが容易といわれています。SX-ACEにおいても、この一般論があてはまり、ノード間並列よりもノード内並列のほうが容易であると言えます。
SX-ACEでのノード内並列は、「自動並列」「OpenMP」といった方法が代表的です。
なお、自動並列化で並列化されなかったり、あるいは明示的に並列化を強制/無効化したい場合には、開発者がソースコードにコンパイラ指示行を挿入して並列化を制御することできます。詳細は、こちらをご覧ください。
(準備中)
OpenMPは共有メモリ並列プログラミングのための標準API(Application Programming Interface)です。文字通り、OpenMPは、共有メモリ型の計算機を対象としています。例えば、以下のように、ソースコードにコンパイラに対する指示行(Compiler Directive)を挿入してコンパイルするだけで、マルチスレッド実行する実行モジュールが自動的に生成されるため、初学者が比較的簡単に着手できる分散並列化手法です。Fortran、CあるいはC++で利用できます。
例1
#pragma omp parallel
{
#pragma omp for
for(i =1; i < 1000; i=i+1) x[i] = y[i] + z[i]; }
例2
!$omp parallel
!$omp do
do i=1, 1000
x(i) = y(i) + z(i)
enddo
!$omp enddo
!$omp end parallel
OpenMPについては、書籍、インターネットから多くの情報を取得できますの で、より詳細な利用方法については、参考にされるとよいでしょう。
ノード間並列(分散メモリ並列処理)
この方法の特徴は、異なるノードの主記憶を利用する計算方法であるため、同一のメモリ空間を共有せず、分散配置され た複数の独立したメモリ空間を利用することにあります。このことが、分散メモリ並列処理が共有メモリ並列処理よりも難しい要因となっています。
SX-ACEでのノード間並列は、「HPF (High-Performance Fortran)」「MPI (Message Passing Interface)」を利用する方法が代表的です。
Message Passing Interfaceはメッセージパッシング方式に基づく分散並列プログラミングのためのライブラリ、API(Application Programming Interface)を規定しています。MPIでは、分散メモリ並列処理環境上で発生しうるMPIプロセス間の通信パターンを想定し、あるプロセスがあるプロセスと通信をおこなう1対1通 信(例えば、MPI_Send, MPI_Recvなど。)、複数のプロセスが同時に関係した通信をおこなう集合通信(例えば、MPI_Bcast, MPI_Reduceなど。)に関する、直感的で分かりやすいAPIを提供します。MPIによる分散並列化では、開発者が複数のMPIプロセス間でのデータ移動、計算負荷分散を考慮しつつ、ソースコードを作成しなければならないため、初学者にはすこし敷居が高い分散並列化手法です。 しかし、計算機システムのハードウェアアーキテクチャや特性を理解してコーディングを行うことができる中・上級者になれば、HPFよりも高性能なソースコードを開発することができるようになるでしょう。なお、今日では、MPIは事 実上標準(de facto standard)になっており、数多くの分散並列化を行うシミュ レーションや解析処理で用いられています。また、今日の計算機アーキテクチャ が”クラスタ化”していることも背景にありますので、MPIは習得しておくのがよ いでしょう。
HPF (High Performance Fortran)は、分散メモリ型並列計算機向けの拡張がなされたFortranであり、現在国際的な標準となっています。
このHPFは、OpenMPと同様に、データや処理の並列化に関するコンパイラに対する指示行(Compiler Directive)をソースコードに挿入してコンパイルするだけで、複数のプロセスで実行する実行モジュールが自動的に生成されます。コンパイラが並列計算に必要となるプロセッサ間の通信や同期の指示を生成してくれるため、初学者にも比較的容易にノード間並列が実現できます。ただし、HPFという名が示す通り、Fortranの拡張ですので、Cではご利用いただけません。
例
!HPF$ PROCESSORS P(4)
!HPF$ DISTRIBUTE (BLOCK) ONTO P :: x,y,z
do i=1, 1000
x(i) = y(i) + z(i)
enddo
【参考資料】
第1回 次期スーパーコンピュータ「SX-ACE」利用説明会資料(2014/09/02開催)
第2回 次期スーパーコンピュータ「SX-ACE」利用説明会資料(2014/11/26開催)
| SX-9 | SX-ACE | |
|---|---|---|
| CPU数(core数) | 16CPU | 1CPU (4core) |
| 最大ベクトル性能 | 1.6TFLOPS | 256TFLOPS (x1/6.4) |
| 主記憶容量 | 1TB | 64GB (x1/16) |
Gallery



更新日時:2020年03月30日 / 大規模可視化対応PCクラスタ(VCC)
本システムは2020年3月31日で提供を終了しました。
2020年4月10日追記:緊急性と必要性を鑑み、昨年度3月31日でサービスを終了した本システムを再配備し、新型コロナウイルス感染症対策対応HPCI臨時公募課題に資源拠出することとしました。
2021年2月追記:新型コロナウイルス感染症対策対応HPCI臨時公募課題への提供を終了しました。
システム概要
大規模可視化対応PCクラスタ(VCC : PC Cluster for large-scale Visualization)は、総計69ノードが相互接続されたクラスタシステムです。66ノードはIntel Xeon E5-2670v2プロセッサ2基、64GBの主記憶容量を搭載しており、残り3ノードはIntel Xeon E5-2690v4 プロセッサ2基、64GBの主記憶容量を搭載しております。これら69ノードを、InfiniBand FDRでノード間接続し、クラスタを形成します。
また、本システムでは、システムハードウェア仮想化技術ExpEtherを導入しており、各ノードと、GPU資源、SSD、ディスクが接続された拡張I/Oノードを20GbpsのExpEtherネットワークで接続します。このノードと拡張I/Oノードの接続組み合わせを変更することで、利用者の利用要求に応じた大規模計算機システムを再構成することができる点を最大の特徴としています。
なお、本センターでは、2PBのディスクをNEC独自開発のNEC Scalable Technology File System (ScaTeFS) と呼ばれる高速・分散並列ファイルシステムで管理し、VCCを含む本センターの大規模計算機システムからアクセス可能な構成としています。
[注意!!] 本システムは、大規模可視化システムとの連動や、可視化用途にしか利用できないというわけではありません。シミュレーションや大規模計算用途にもご利用いただけます。
ExpEtherは、イーサネット(Ethernet)上でPCI Expressを仮想化する技術です。これにより、通常の計算機内の内部バスを、イーサネット上にスケールアップすることが可能となります。
ノード性能
各ノードは、200GFlopsの演算性能を有するIntel Xeon E5-2670v2プロセッサ2基、64GBの主記憶容量を搭載しています。Intel Xeon E5-2670v2プロセッサは、その動作周波数は2.5GHz、内部に10コアを搭載しており、プロセッサ単体の演算性能は200GFlopsです。そのため、ノード単体では合計20コア、ノード単体の演算性能は400GFlopsとなります。
ノード間の通信は、InfiniBand FDRで接続され、双方向56Gbpsの最大転送容量を提供します。
| 1ノード(VCC) | |
|---|---|
| プロセッサ(コア)数 | 2(20)個 |
| 主記憶容量 | 64GB |
| ディスク容量 | 1TB |
| 演算性能 | 400GFlops |
2017年4月追記
構成の異なる3ノードを増設しました。(以下、増設ノードという)
増設ノードは、Intel Xeon E5-2690v4 プロセッサ2基、64GBの主記憶容量を搭載しています。Intel Xeon E5-2690v4プロセッサは、その動作周波数は3.5GHz(ターボブースト使用)、内部に14コアを搭載しており、プロセッサ単体の演算性能は784GFlopsです。そのため、ノード単体では合計28コア、ノード単体の演算性能は1568GFlopsとなります。
| 1ノード(VCC増設分) | |
|---|---|
| プロセッサ(コア)数 | 2(28)個 |
| 主記憶容量 | 64GB |
| ディスク容量 | 1TB |
| 演算性能 | 1568GFlops |
システム性能
大規模可視化対応PCクラスタ(VCC)は、総計69ノードから構成されます。そのため、システム全体の理論性能値は下記のように導かれます。
| 大規模可視化対応PCクラスタ(VCC) | |
|---|---|
| プロセッサ(コア)数 | 138(1404)個 |
| 主記憶容量 | 4.278TB |
| ディスク容量 | 62TB |
| 演算性能 | 31.104TFlops |
また、VCCは、各ノードに対して、システムハードウェア仮想化技術ExpEtherを用いることで、ユーザのニーズに応じて、下記の再構成可能資源を割り付けることができます。現在、再構成可能資源として提供している資源は下記の通りです。現在、再構成可能資源として提供している資源は下記の通りです。
1ノードに対してすべての再構成可能資源を割り付けることができるわけではなく、1ノードあたりに割り付けることのできる最大資源数が限られています。しかし、SSDとGPUといった再構成可能資源を組み合わせて割り付けることが可能です。
ご興味・関心のある方は下記までお問い合わせください。
system at cmc.osaka-u.ac.jp
| 再構成可能資源 | 資源数 | 性能値 |
|---|---|---|
| GPU:Nvidia Tesla K20 | 59枚 | 69.03TFlops |
| SSD:ioDrive2(365GB) | 4枚 | 1.46TB |
| Storage:PCIe SAS (36TB) | 9枚 | 324 TB |
ソフトウェア
本センターのVCCには、オペレーティングシステムとしてCent OS 6.4が採用されています。そのため、日常的にLinux系OS上でプログラム開発をされている方にとっては、利用、プログラムの移植・開発が非常に容易なシステムとなっています。
現在、本システムで利用できるソフトウェアとして下記を提供しています。
| ソフトウェア |
|---|
| Intel C/C++/Fortran Compiler |
| Intel MPI |
| Intel MKL(BLAS、LAPACKをはじめとする密線形台数、スパース線形代数、統計関数、ScaLAPACK、クラスター FFT、高速フーリエ変換 (FFT)、最適化された LINPACK ベンチマーク、ベクトル・マス・ライブラリー) |
| AVS/Express PCE |
| AVS/Express MPE (Ver.8.1) |
| Gaussian09 |
| GROMACS |
| OpenFOAM |
| LAMMPS |
| プログラミング言語 |
|---|
| C/C++(Intel Compiler/GNU Compiler) |
| FORTRAN(Intel Compiler/GNU Compiler) |
| Python |
| Octave |
| Julia |
なお、VCCへのジョブ管理には、Job ManipulatorとNQSIIを中核とした統合スケジューラを採用しています。スケジューラについては下記をご参照ください。
スケジューラについて
VCCでの性能チューニング
VCC上で性能チューニングを行う方法には、大別して、ノード内並列(共有メモリ並列)、ノード間並列(分散メモリ並列処理)の2種類があります。前者のノード内並列処理は、VCCのノード内に搭載された20個のCPUコアで計算負荷を分散する方法です。後者のノード間並列処理は、VCCの複数のノードに計算負荷を分散する方法です。
VCCで最大限の性能を引き出すためには、ノード内並列とノード間並列を併用する必要があります。VCCでは特に1ノードあたりに搭載されたコア数が多いため、主記憶容量64GBの範囲で計算が可能な場合には、ノード内並列で20コアを最大限に分散並列化が効果的ともいえます。
さらに、VCCでは再構成可能資源としてGPUやSSDが準備されていますので、GPUを用いた高速化を行ったり、SSDを用いてローカルディスクへのI/Oを高速化するなどの工夫によって、さらにチューニングを進めることもできます。
ノード内並列(共有メモリ並列処理)
この方法の特徴は、スカラ型CPU20コアが主記憶64GBのメモリ空間を”共有”することにあります。一般的に、分散並列計算においては、分散メモリ型のほうがプログラミング、チューニングが容易といわれています。VCCにおいても、この一般論があてはまり、ノード間並列よりもノード内並列のほうが容易であると言えます。
VCCでのノード内並列は、「OpenMP」、「スレッド」といった方法が代表的です。なお、一般的には、ノード間並列処理で用いられる「MPI」をノード内並列で用いることもできます。
OpenMPは共有メモリ並列プログラミングのための標準API(Application Programming Interface)です。文字通り、OpenMPは、共有メモリ型の計算機を対象としています。例えば、以下のように、ソースコードにコンパイラに対する指示行(Compiler Directive)を挿入してコンパイルするだけで、マルチスレッド実 行する実行モジュールが自動的に生成されるため、初学者が比較的簡単に着手できる分散並列化手法です。Fortran、CあるいはC++で利用できます。
例1
#pragma omp parallel
{
#pragma omp for
for(i =1; i < 1000; i=i+1) x[i] = y[i] + z[i]; }
例2
!$omp parallel
!$omp do
do i=1, 1000
x(i) = y(i) + z(i)
enddo
!$omp enddo
!$omp end parallel
OpenMPについては、書籍、インターネットから多くの情報を取得できますの で、より詳細な利用方法については、参考にされるとよいでしょう。
スレッド(thread)は軽量プロセスとよばれる、プロセスよりも細かい処理の単位です。プロセス単位でCPU利用を制御するよりもスレッド単位でCPU利用を制御するほうが、それらを実行するための情報の切り替えが高速に行われるため、計算処理が高速になることがあります。
ただし、VCCでスレッドを利用する際は、スケジューラにジョブを投入する際に、
#PBS -l cpunum_job=20
として、ノード内のCPUコアをすべて利用する宣言を行わなければなりません。
ノード間並列(分散メモリ並列処理)
この方法の特徴は、異なるノードの主記憶を利用する計算方法であるため、同一のメモリ空間を共有せず、分散配置された複数鵜の独立したメモリ空間を利用することにあります。このことが、分散メモリ並列処理が共有メモリ並列処理よりも難しい要因となっています。
VCCでのノード間並列は、「MPI(Message Passing Interface)」を利用する方法が代表的です。
Message Passing Interfaceはメッセージパッシング方式に基づく分散並列プ ゴラミングのためのライブラリ、API(Application Programming Interface)を規 定しています。MPIでは、分散メモリ並列処理環境上で発生しうるMPIプロセス間の通信パターンを想定し、あるプロセスがあるプロセスと通信をおこなう1対1通 信(例えば、MPI_Send, MPI_Recvなど。)、複数のプロセスが同時に関係した通信をおこなう集合通信(例えば、MPI_Bcast, MPI_Reduceなど。)に関する、直感的で分かりやすいAPIを提供します。MPIによる分散並列化では、開発者が複数のMPIプロセス間でのデータ移動、計算負荷分散を考慮しつつ、ソースコードを作成しなければならないため、初学者にはすこし敷居が高い分散並列化手法です。 しかし、計算機システムのハードウェアアーキテクチャや特性を理解してコー ディングを行うことができる中・上級者になれば、HPFよりも高性能なソースコードを開発することができるようになるでしょう。なお、今日では、MPIは事 実上標準(de facto standard)になっており、数多くの分散並列化を行うシミュレーションや解析処理で用いられています。また、今日の計算機アーキテクチャが”クラスタ化”していることも背景にありますので、MPIは習得しておくのがよいでしょう。
GPUを用いた高速化
VCCには、Nvidia Tesla K20というGPUが59枚再構成可能資源として準備されています。このGPUを、例えば、VCCを構成する4ノードに2個ずつ割り付け、8個のGPUを用いたアクセラレーションを行うことも可能です。本センターのGPUでの開発環境としては、CUDA(Compute Unified Device Architecture)が準備されています。
関心の有る方は、こちらより情報が取得できます。
更新日時:2020年03月15日 / 24面大型立体表示システム
本システムの提供は終了しました。
システム概要
24面大型立体表示システム(24-screen Flat Stereo Visualization System)は、Full HD (1920×1080) 50インチステレオプロジェクションモジュール(Barco社製 OLS-521 ) 24面、および、24面モニタ上での可視化処理を制御する画像処理用PCクラスタ(Image-Processing PC Cluster)から構成される可視化システムです。本可視化システムは、水平150度の広視野角で約5000万画素の超高精細立体表示を可能とする点を特徴とします。また、大規模可視化対応PCクラスタ(VCC)を占有利用することで、本可視化システムと連動させた可視化処理を可能とする点を最大の特徴とします。
また、本可視化システムには、モーションキャプチャリングシステムOptiTrack Flex13が導入されており、対応ソフトウェアを利用することで、VR(Virtual Reality)機能を利用したインタラクティブな可視化が可能です。
さらに、ハイビジョンビデオ会議システム(Panasonic製KX-VC600)もありますので、テレビ会議利用も可能となっています。
ノード性能
本可視化システムを構成する画像処理用PCクラスタ(IPC-C: Image-Processing PC Cluster on Campus)は、Intel Xeon E5-2640 2.5GHzプロセッサ2基、主記憶容量64GB、ハードディスク2TB(RAID 1構成)、NVIDIA製Quadro K5000を備えた計算機7台から構成されています。本可視化システムでは、この画像処理用PCクラスタを相互連携させ、24面モニタ上での可視化処理を制御しています。
| 1ノード(IPC-C) | |
|---|---|
| プロセッサ(コア)数 | 2(12) 個 |
| 主記憶容量 | 64 GB |
| ディスク容量 | 2TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 1個 |
| 演算性能 | 240 GFlops |
システム性能
IPC-Cは、7ノードが10GbEで接続されたクラスタシステムです。IPC-Cの理論性能値は以下の通りです。
| IPC-C | |
|---|---|
| プロセッサ(コア)数 | 14(84)個 |
| 主記憶容量 | 448 GB |
| ディスク容量 | 14 TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 7個 |
| 演算性能 | 1.68 TFlops |
ソフトウェア
本可視化システムを構成する画像処理用PCクラスタ(IPC-C)には、オペレーティングシステムとして、Windows 7 ProfessionalおよびCent OS 6.4がデュアルブート可能な形でインストールされています。利用用途に応じてオペレーティングシステムはお選び頂けます。
このIPC-Cには、可視化ソフトウェア、VRユーティリティソフトウェアとして下記のソフトウェア群が導入されています。
可視化ソフトウェア
| AVS Express/MPE VR | 汎用可視化ソフトウェア。CAVE などのVRディスプレイにも対応。 |
|---|---|
| IDL | データ分析,可視化,ソフトウェア開発環境を持った統合パッケージ |
| Gsharp | グラフ・コンター図作成ツール. |
| SCANDIUM | SEMデータの画像解析処理 |
| ヴェイサエンターテイメント社製Umekita | 電子顕微鏡等の計測機器から出力される立体構造のデータを高品質に可視化 |
VRユーティリティ
| CAVELib | マルチディスプレイ,PCクラスタ環境下で可視化を行うためのAPI |
|---|---|
| EasyVR MH Fusion VR | 3D-CAD/CGソフトウェア上の3DモデルをVRディスプレイに表示するソフトウェア(データコンバート不要) |
| VR4MAX | 3ds Max上の3DモデルをVRディスプレイに表示するためのソフトウェア |
更新日時:2014年09月15日 / 15面シリンドリカル立体表示システム
本システムの提供は終了しました。
システム概要
15面シリンドリカル立体表示システム(15-screen Cylindrical Stereo Visualization System)は、WXGA (1366×768) 46インチLCD 15面、および、15面モニタ上での可視化処理を制御する画像処理用PCクラスタ(Image-Processing PC Cluster)から構成される可視化システムです。本可視化システムは、約1600万画素の超高精細立体表示を可能とする点を特徴とします。また、大規模可視化対応PCクラスタ(VCC)を占有利用することで、本可視化システムと連動させた可視化処理を可能とする点を最大の特徴とします。
また、本可視化システムには、モーションキャプチャリングシステムOptiTrack Flex13が導入されており、対応ソフトウェアを利用することで、VR(Virtual Reality)機能を利用したインタラクティブな可視化が可能です。
さらに、ハイビジョンビデオ会議システム(Panasonic製KX-VC600)もありますので、テレビ会議利用も可能となっています。
本可視化システムの設置場所は、大阪大学サイバーメディアセンターうめきた拠点(グランフロント大阪 タワーC 9階 大阪大学エリア)です。
ノード性能
本可視化システムを構成する画像処理用PCクラスタ(IPC-U: Image-Processing PC Cluster on Umekita)は、Intel Xeon E5-2640 2.5GHzプロセッサ2基、主記憶容量64GB、ハードディスク2TB(RAID 1構成)、NVIDIA製Quadro K5000を備えた計算機6台から構成されています。本可視化システムでは、この画像処理用PCクラスタを相互連携させ、15面モニタ上での可視化処理を制御しています。
| 1ノード(IPC-U) | |
|---|---|
| プロセッサ(コア)数 | 2(12)個 |
| 主記憶容量 | 64 GB |
| ディスク容量 | 2 TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 1個 |
| 演算性能 | 240 GFlops |
システム性能
IPC-Uは、6ノードが10GbEで接続されたクラスタシステムです。IPC-Uの理論性能値は以下の通りです。
| IPC-U | |
|---|---|
| プロセッサ(コア)数 | 12(72)個 |
| 主記憶容量 | 384 GB |
| ディスク容量 | 12 TB (RAID 1) |
| GPU: NVidia Quadro K5000 | 6個 |
| 演算性能 | 1.44 TFlops |
ソフトウェア
本可視化システムを構成する画像処理用PCクラスタ(IPC-U)には、オペレーティングシステムとして、Windows 7 ProfessionalおよびCent OS 6.4がデュアルブート可能な形でインストールされています。利用用途に応じてオペレーティングシステムはお選び頂けます。
このIPC-Uには、可視化ソフトウェア、VRユーティリティソフトウェアとして下記のソフトウェア群が導入されています。
可視化ソフトウェア
| AVS Express/MPE VR | 汎用可視化ソフトウェア.CAVE などのVRディスプレイにも対 |
|---|---|
| IDL | データ分析,可視化,ソフトウェア開発環境を持った統合パッケー |
| Gsharp | グラフ・コンター図作成ツール |
| SCANDIUM | SEMデータの画像解析処理 |
| ヴェイサエンターテイメント社製Umekita | 電子顕微鏡等の計測機器から出力される立体構造のデータを高品質に可視化 |
VRユーティリティ
更新日時:2014年07月16日 / 汎用コンクラスタ(HCC)
本システムの提供は終了しました。後継機のOCTOPUSをご利用ください。(提供期間:提供期間:2013年4月-2017年9月)
システム概要
2012年10月より、Express5800/53Xh×575台上の仮想Linuxをクラスタシステムとして演算サービスを提供しています。
Express5800/53Xh は CPUがIntel Xeon E3-1225v2(1CPU 4コア)、メモリが8GB/16GBの性能を持ちますが、仮想Linuxでは 2コア、4GB/12GB が利用可能です。仮想LinuxのOSはCent OS 6.1、Intel製の C/C++ 及び Fortran コンパイラを導入しています。また、Intel MPI ライブラリーを用いたMPI 並列計算が可能です。
システム性能
| 豊中地区 | 吹田地区 | 箕面地区 | ||||
|---|---|---|---|---|---|---|
| ノード毎 | 総合 | ノード毎 | 総合 | ノード毎 | 総合 | |
| プロセッサ数 | 2 | 536 | 2 | 338 | 2 | 276 |
| 演算性能 | 28.8 GFLOPS | 7.7 TFLOPS | 28.8 GFLOPS | 4.9 TFLOPS | 28.8 GFLOPS | 4.0 TFLOPS |
| 主記憶容量 | 4GB | 1.1TB | 4/12GB | 1.2TB | 4GB | 0.6TB |
| ノード数 | 268ノード | 169ノード | 138ノード | |||
| 全ノード数 | 575ノード | |||||
※ 3地区に分散して設置しています。
汎用コンクラスタ(HCC)利用における注意事項
ホストOSを学生教育用の端末PCとして利用している関係上、突然のノード停止が発生する可能性があります。この停止は事前に予測できずに発生いたしますので、投入されたバッチリクエストの動作に影響する可能性があることをご了承ください。
更新日時:2014年07月15日 / SX-9
本システムの提供は終了しました。(提供期間:2008年7月1日-2014年9月12日)後継機のSX-ACEをご利用ください。
SX-9のCPUはプロセッサ当たり102.4GFLOPSの性能を持ち、各ノードには16個を搭載、ノード毎の演算性能は1.6TFLOPS、主記憶容量は1TBを有します。
10ノードの総合演算性能は16TFLOPS、総合メモリは10TBの大規模システムになり、MPIを用いた並列処理により最高で8ノード(12.8TFLPS, 8TBメモリ)の演算が可能です。
更新日時:2014年07月14日 / SX-8R
本システムの提供は終了しました。(提供期間:2007年1月5日-2014年9月12日)後継機のSX-ACEをご利用ください。
SX-8Rは、大容量メモリ型(DDR2)8ノードと高速メモリ型(FC-RAM)12ノードの2種類の機種から構成されます。各ノードには8個のCPUを搭載し、ノード毎の演算性能は大容量メモリ型が281.6GFLOPS、高速メモリ型が256GFLOPSとなっています。
また、主記憶容量は大容量メモリ型が256GB、高速メモリ型は4ノードが64GB、8ノードが128GBとなっています。
大容量メモリ型の8ノードは、ノード間接続装置(IXS)で接続され、MPIプログラミングにより最大2TBメモリの演算が可能です。
更新日時:2014年07月14日 / PCクラスタ(PCC)
本システムの提供は終了しました。ご利用ありがとうございました。(提供期間:2007年3月-2014年3月)
Express5800/120Rg-1×128台でPCクラスタシステムとして演算サービスを提供しています。
Express5800/120Rg-1 は CPU が Intel Xeon 3GHz (Woodcrest) 2CPU 4コア、メモリが 16GB の性能を持ちます。
OS は SUSE Linux Enterprise Server 10、Intel 製の C/C++ 及び Fortran コンパイラを導入しています。
また、MPI-CH 1.2.7p1 及び Intel MPI ライブラリー を用いた MPI 並列演算が可能です。
更新日時:2007年01月19日 / SX-5
本システムの提供は終了しました。(提供期間:2001年1月-2007年1月)
SX-5/128M8は16個のベクトルプロセッサと128GBの主記憶を搭載したNEC SX-5/16Afの8ノードと、64Gbpsの専用ノード間接続装置IXS、800MbpsのHiPPIおよび1GbosのGigabit Ethernetによって接続したクラスタ型スーパーコンピューティングシステムです。
システム全体の仕様
| 理論演算性能 | 1.2 TFLOPS |
|---|---|
| ノード数 | 8 |
| CPU数 | 128 |
| 定格消費電力 | 443.36 kVA |
1ノードあたりの仕様
| CPU | NEC SX-5/16Af |
|---|---|
| CPU数 | 16 |
| メモリ容量 | 128 GB |
| メモリ帯域 | 16 GB/s |
| 理論演算性能 | 160 GFLOPS |
| 定格消費電力 | 55.42 kVA |
